
Trong bài trước, chúng ta đã hình dung Kubernetes như một nhạc trưởng điều phối các container. Nhưng để dàn nhạc chơi được, các nhạc công phải nghe thấy nhau. Hệ thống mạng (Networking) trong Kubernetes là một kiệt tác về kỹ thuật, nhưng cũng là một bãi mìn về hiệu năng và bảo mật nếu bạn không hiểu rõ bản chất hoạt động của nó ở tầng Kernel.
Bài viết này sẽ bóc tách các khái niệm cốt lõi nhất và theo dấu một gói tin (packet) để xem nó thực sự đi qua những đâu.
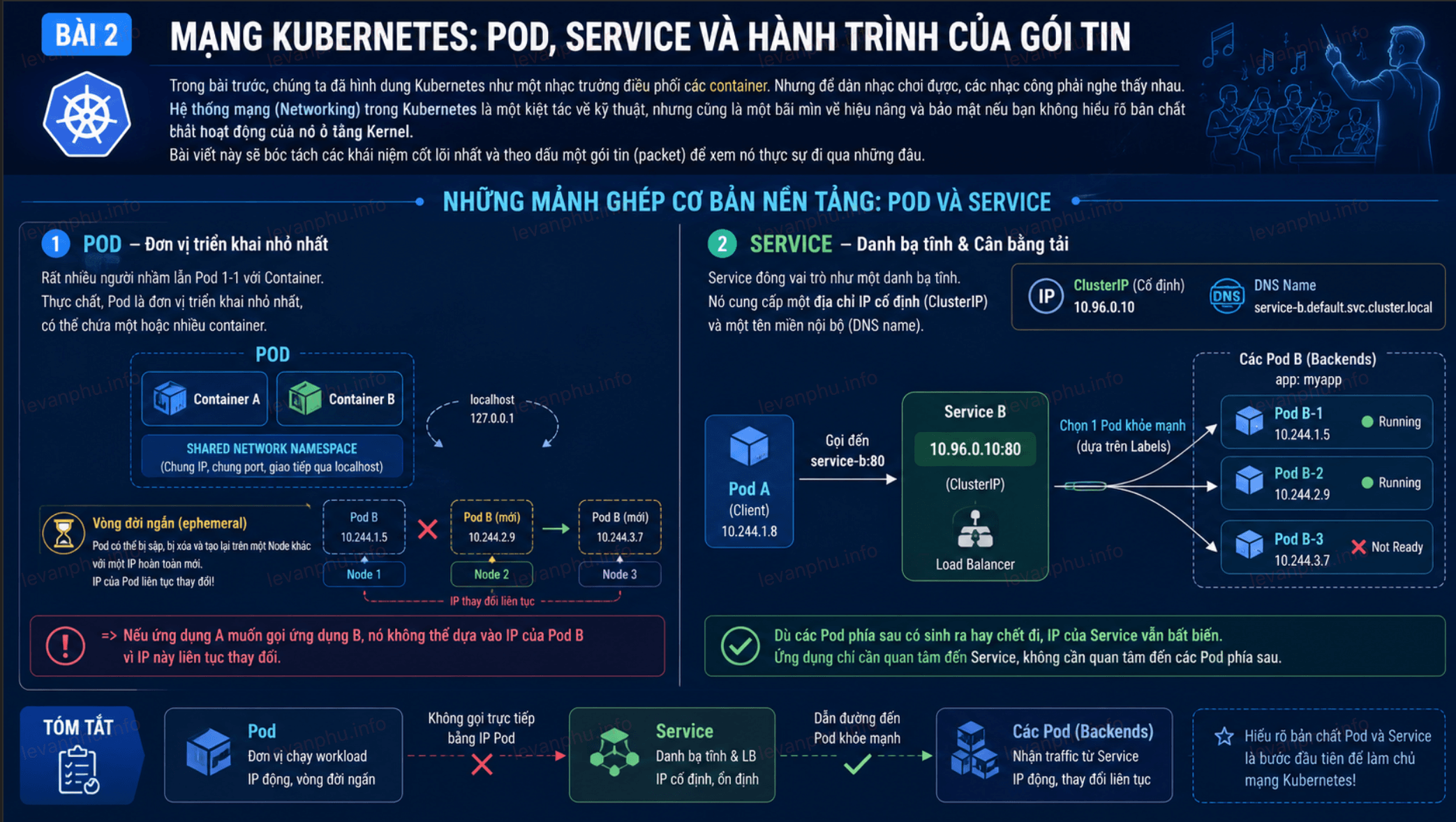
Những mảnh ghép cơ bản nền tảng Pod và Service
Để hiểu mạng Kubernetes, trước tiên phải hiểu hai đối tượng nền tảng là Pod và Service.
Pod không chỉ là một container: Rất nhiều người nhầm lẫn Pod 1-1 với Container. Thực chất, Pod là đơn vị triển khai nhỏ nhất, có thể chứa một hoặc nhiều container. Điểm mấu chốt là các container trong cùng một Pod sẽ chia sẻ chung một Network Namespace. Nghĩa là chúng dùng chung một địa chỉ IP, chung không gian port và có thể giao tiếp với nhau qua localhost.
Tuy nhiên, Pod có vòng đời rất ngắn (ephemeral). Chúng có thể bị sập, bị xóa và tạo lại trên một Node khác với một IP hoàn toàn mới. Nếu ứng dụng A muốn gọi ứng dụng B, nó không thể dựa vào IP của Pod B vì IP này liên tục thay đổi.
Đó là lúc Service xuất hiện: Service đóng vai trò như một danh bạ tĩnh. Nó cung cấp một địa chỉ IP cố định (ClusterIP) và một tên miền nội bộ (DNS name). Khi Pod A gọi đến Service B, Service B sẽ làm nhiệm vụ cân bằng tải (Load Balancing) và đẩy traffic đến đúng các Pod B đang còn sống (dựa trên cơ chế gắn nhãn - Labels). Dù các Pod phía sau có sinh ra hay chết đi, IP của Service vẫn bất biến.
Sai lầm về Kubernetes Service
Rất nhiều người hiểu sai rằng:
“Kubernetes Service là một process load balancing”
Trong khi thực tế:
- Service chỉ là virtual abstraction
- kube-proxy mới là thứ thao tác iptables/IPVS
- kernel mới là nơi packet được xử lý thật
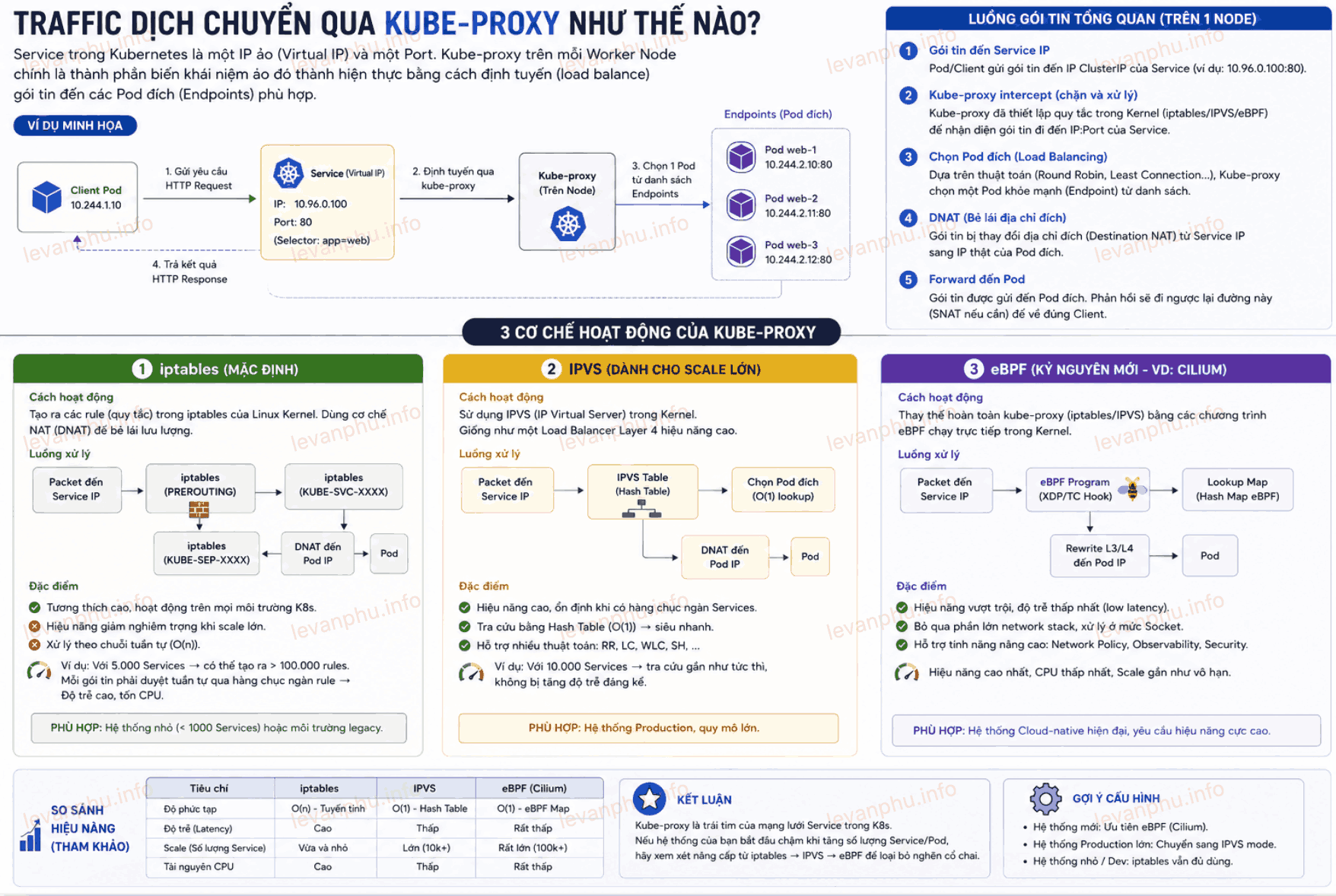
Trafic dịch chuyển qua Kube-proxy như thế nào
Nói Service làm nhiệm vụ Load Balancing, nhưng thực tế Service không phải là một con Nginx hay HAProxy chạy vật lý. Nó là một khái niệm ảo được thực thi bởi kube-proxy – một thành phần chạy trên mọi Worker Node.
Cách kube-proxy định tuyến gói tin (packet routing) quyết định trực tiếp đến độ trễ của toàn bộ hệ thống:
Chế độ iptables (Mặc định): Kube-proxy sẽ tạo ra các quy tắc iptables trong Linux Kernel để chặn các gói tin đi đến IP của Service và bẻ lái (NAT) chúng sang IP của Pod đích. Vấn đề là iptables xử lý các rule theo chuỗi tuần tự (O(n)). Nếu bạn có 5.000 Services, hệ thống phải duyệt qua hàng chục ngàn rule cho mỗi gói tin. Điều này tạo ra độ trễ cực lớn và nghẽn cổ chai CPU.
Chế độ IPVS: Dành cho các hệ thống scale lớn. IPVS (IP Virtual Server) cũng nằm trong Kernel nhưng sử dụng cấu trúc dữ liệu Hash Table (O(1)). Dù bạn có 10.000 Services, thời gian tra cứu và định tuyến vẫn gần như ngay lập tức.
Kỷ nguyên eBPF (Cilium): Những hệ thống hiện đại nhất hiện nay thậm chí đã loại bỏ hoàn toàn kube-proxy và iptables để chuyển sang eBPF. Kỹ thuật này cho phép chạy các chương trình định tuyến trực tiếp bên trong nhân Linux mà không cần đi qua toàn bộ network stack, giúp giảm độ trễ (latency) xuống mức thấp nhất và tăng throughput lên tối đa.
Bảng so sánh: iptables vs IPVS vs eBPF
Để hình dung rõ hơn sự tiến hóa của mạng lưới Kubernetes và lý do các kiến trúc lớn đang dần loại bỏ iptables, hãy cùng xem qua bảng so sánh bản chất xử lý gói tin ở tầng Kernel:
| Mode | Đặc điểm kiến trúc | Khả năng mở rộng (Scalability) | Hiệu năng & Độ trễ | Vị thế trong Hệ sinh thái |
| iptables | Linear rule matching (O(n)). Duyệt tuần tự qua danh sách các quy tắc. | Kém. Xảy ra nghẽn cổ chai CPU khi số lượng Service vượt mốc 5.000. | Độ trễ cao do packet phải đi qua toàn bộ Netfilter stack. | Là chế độ mặc định, phù hợp với các cluster nhỏ nhưng đang dần lỗi thời. |
| IPVS | Kernel load balancer sử dụng cấu trúc Hash Table (O(1)). | Tốt. Xử lý hàng chục ngàn Service với thời gian tra cứu gần như không đổi. | Tối ưu route tốt hơn, giảm thiểu độ trễ đáng kể so với iptables. | Lựa chọn nâng cấp tiêu chuẩn cho các hệ thống cần scale mạnh. |
| eBPF (Cilium) | Bypass hoàn toàn iptables. Hook trực tiếp mã thực thi vào nhân Linux. | Xuất sắc. Phân luồng traffic và định tuyến packet ở tốc độ cực đại. | Độ trễ cực thấp. Gói tin có thể đi thẳng từ Card mạng (NIC) tới Socket. | Tương lai của K8s. Đang trở thành chuẩn mực mới (de-facto) cho hạ tầng mạng. |
Sự dịch chuyển tất yếu sang hệ sinh thái eBPF/Cilium
Hiện nay, hệ sinh thái Cloud Native đang chứng kiến một cuộc "lột xác" mạnh mẽ khi các hệ thống dần từ bỏ kube-proxy truyền thống để chuyển sang sử dụng công nghệ eBPF (Extended Berkeley Packet Filter), với đại diện tiên phong là CNI Cilium.
Thay vì để gói tin phải chật vật đi qua một "mê cung" các quy tắc của Netfilter, eBPF cho phép chúng ta lập trình và gắn trực tiếp các logic mạng, định tuyến vào sâu bên trong nhân hệ điều hành một cách an toàn. Sự can thiệp ở tầng thấp này mang lại những giá trị vượt trội:
Hiệu năng mạng tiệm cận "Bare-metal": Triệt tiêu hoàn toàn overhead của kube-proxy, giúp tăng throughput và giảm độ trễ (latency) xuống mức thấp nhất.
Bảo mật vi mô (Micro-segmentation) ở tốc độ cao: Việc thực thi Network Policies giờ đây diễn ra ngay tại Kernel, hỗ trợ đắc lực cho các kiến trúc Zero Trust hay SASE trong môi trường container mà không làm suy giảm hiệu năng.
Khả năng quan sát (Observability) sâu sắc: eBPF cho phép theo dõi mọi luồng traffic, từ mức IP, Port cho đến HTTP path hay DNS query mà không cần chèn thêm các sidecar proxy nặng nề.
Đối với các kỹ sư vận hành hạ tầng, việc nắm bắt eBPF không chỉ đơn thuần là thay thế một plugin mạng, mà là bước chuyển mình bắt buộc để xây dựng một kiến trúc an toàn, minh bạch và sẵn sàng mở rộng không giới hạn.
Sơ đồ Packet Flow trong Kubernetes
Để dễ hình dung đường đi của một gói tin (packet), chúng ta hãy cùng xem xét hai kịch bản phổ biến nhất:
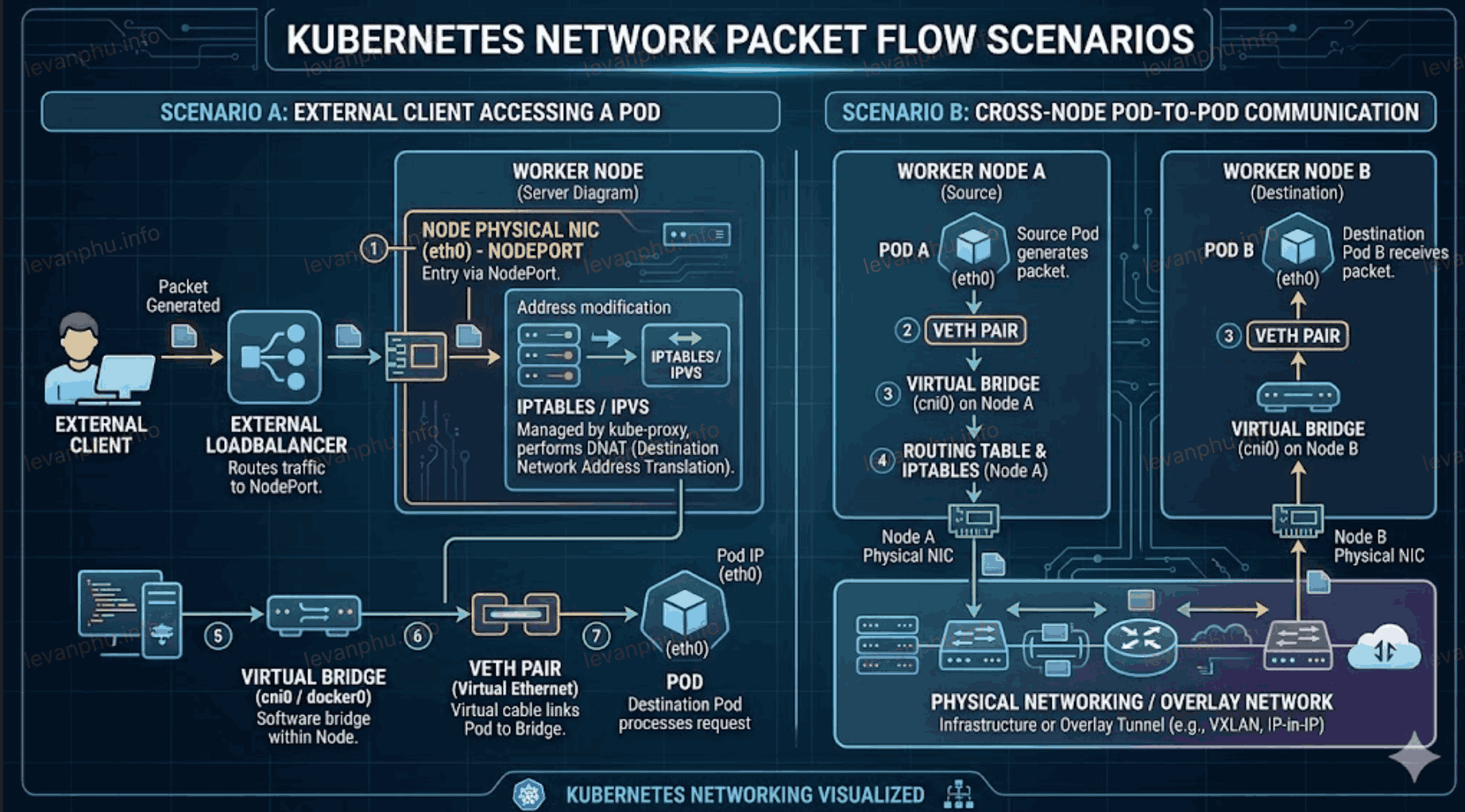
Kịch bản A: Traffic từ bên ngoài (External Client) truy cập vào Pod Gói tin đi từ người dùng bên ngoài, qua LoadBalancer, đập vào NodePort và được định tuyến đến đúng Pod thông qua các rules mà kube-proxy đã cấu hình.
Kịch bản B: Giao tiếp giữa Pod với Pod khác Node (Cross-Node Traffic) Khi hai Pod nằm trên hai Node khác nhau nói chuyện với nhau, gói tin phải đi xuống tầng vật lý của Node nguồn và chui lên lại ở Node đích.
Rủi ro mạng phẳng và giải pháp kiểm soát bằng Network Policies
Dưới góc nhìn bảo mật, mạng Kubernetes mặc định là một cơn ác mộng. Hệ thống này được thiết kế theo nguyên tắc mạng phẳng (Flat Network) tức là mọi Pod đều có thể giao tiếp trực tiếp với mọi Pod khác trên mọi Node mà không bị cản trở (Default Allow).
Hãy tưởng tượng bạn có Pod Frontend (chạy Web) và Pod Backend (chạy Database). Nếu một hacker khai thác được lỗ hổng RCE trên Web và chiếm quyền Pod Frontend, hắn có thể ping, scan port và truy cập thẳng vào Pod Database mà không gặp bất kỳ rào cản nào. Kỹ thuật này gọi là Lateral Movement (Di chuyển ngang).
Để chặn đứng rủi ro này, chúng ta bắt buộc phải sử dụng Network Policies. Đây là cơ chế Tường lửa nội bộ (Micro-segmentation) của Kubernetes, được thực thi bởi các CNI (Container Network Interface) như Calico hay Cilium.
Best Practice: Áp dụng nguyên tắc Zero Trust bằng cách thiết lập cấu hình Default Deny All. Cấm toàn bộ traffic vào/ra trong một Namespace. Sau đó, bạn mới mở lại (Whitelist) một cách cụ thể, ví dụ chỉ cho phép Pod Frontend được phép gọi đến port 5432 của Pod Database. Mọi kết nối đi chệch khỏi quy tắc này sẽ bị drop ở ngay tầng Kernel.
Hành trình chi tiết của một gói tin từ Internet đến đúng Pod
Để tổng hợp lại, hãy theo dấu một gói tin từ trình duyệt của người dùng cho đến khi nó chạm vào ứng dụng của bạn trong Kubernetes:
Từ Internet đến Load Balancer: Người dùng gõ tên miền của ứng dụng. Request đập vào Cloud Load Balancer (AWS ALB, Google Cloud Load Balancer) nằm ngoài hệ thống Kubernetes.
Vào Ingress Controller: Load Balancer đẩy traffic vào Ingress Controller (thường là Nginx hoặc Traefik) chạy bên trong Cluster. Ingress đọc HTTP Header (Host, Path) để biết gói tin này muốn đi đến dịch vụ nào.
Qua Service để tra cứu mạng: Ingress Controller tra cứu và đẩy gói tin đến Service tương ứng. Tại đây, iptables hoặc IPVS trên Node sẽ bẻ lái gói tin (Destination NAT), thay IP đích từ IP của Service thành IP của một Pod thực tế đang rảnh rỗi.
Xuyên qua CNI đến Container: Gói tin đi qua mạng Overlay (như VXLAN/IPIP do Calico/Flannel quản lý) để đến đúng Worker Node chứa Pod. Cuối cùng, nó chui qua cặp giao diện mạng ảo (veth pair) để vào đúng Network Namespace của Pod và được ứng dụng xử lý.
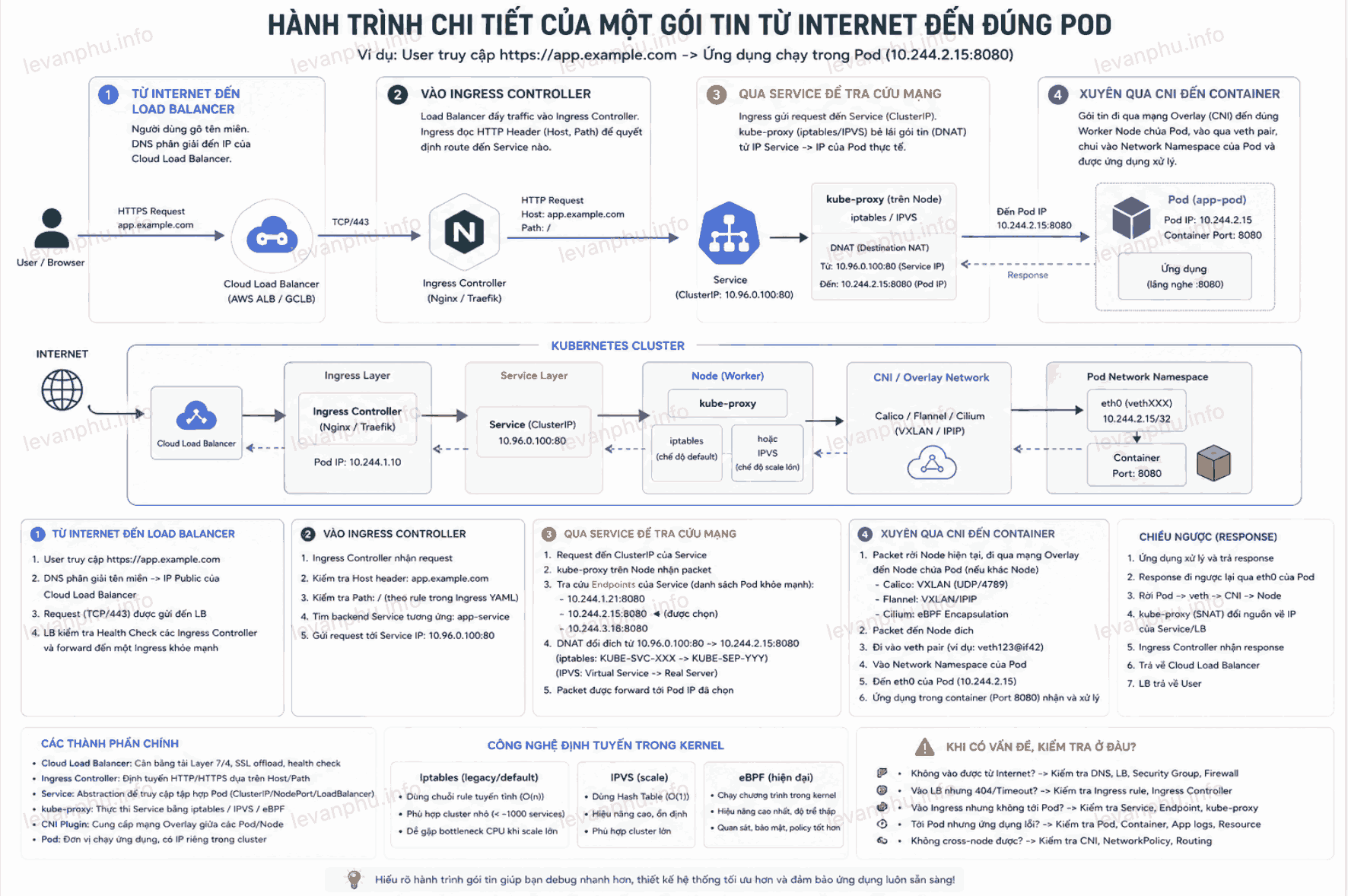
Toàn bộ quy trình phức tạp này diễn ra trong vài mili-giây. Hiểu được luồng đi này, khi hệ thống báo lỗi Timeout hoặc không thể kết nối, bạn sẽ biết chính xác mình cần kiểm tra ở Ingress, ở Service hay ở chính bản thân Pod.
Bộ công cụ Trace Packet & Debug mạng Kubernetes
Hiểu lý thuyết là một chuyện, nhưng khi hệ thống sập hay rớt kết nối, bạn cần công cụ để "nhìn thấy" gói tin đang đi đâu về đâu. Dưới đây là bộ công cụ không thể thiếu để debug packet-level trực tiếp trên Node:
Kiểm tra đầu cuối (Endpoints) và Card mạng
Trước tiên, bạn cần biết IP của Pod và Node đang giao tiếp là gì.
kubectl get endpoints <service-name>
#Kiểm tra xem Service đã map đúng IP của các Pod backend chưa. Nếu danh sách này trống, packet chắc chắn sẽ bị drop.
ip link
#Liệt kê các interface mạng trên Node (bạn sẽ thấy các interface ảo veth, cni0 hoặc flannel.1 ở đây).
ip route
#Kiểm tra bảng định tuyến của Node để xem packet đến dải IP của Pod sẽ bị đẩy ra interface nào.Phân tích Rules và NAT (Network Address Translation)
Nếu packet đi đến Node nhưng không vào được Pod, khả năng cao nó đã bị kẹt ở iptables.
iptables-save | grep <tên-service hoặc pod-ip>
# Dump toàn bộ rules của iptables và tìm kiếm chuỗi liên quan đến Service/Pod của bạn. Công cụ này giúp bạn thấy rõ Kube-proxy đã viết rule KUBE-SVC và KUBE-SEP như thế nào.
conntrack -L | grep <pod-ip>
# Theo dõi trạng thái của các kết nối đang mở (Connection Tracking). Cực kỳ hữu ích để debug lỗi liên quan đến SNAT/DNAT khi packet bị "mất dấu" lúc quay về.Bắt gói tin trực tiếp (Packet Capture)
Khi cần bằng chứng rõ ràng nhất, hãy dùng các công cụ phân tích luồng traffic:
tcpdump -i any host <pod-ip> -n -nn
# Lệnh "thần thánh" giúp bạn tóm sống mọi packet đi ra/đi vào IP của Pod trên tất cả các interface của Node. Tham số -n -nn giúp không phân giải tên miền để tăng tốc độ hiển thị.
ss -antp
# Kiểm tra xem các port bên trong Pod hoặc trên Node đã thực sự có process nào lắng nghe (LISTEN) chưa, hay kết nối đang bị kẹt ở trạng thái SYN_SENT.Mẹo nhỏ thực chiến: Khi debug mạng K8s, hãy bắt đầu trace từ ngoài vào trong: Kiểm tra Node -> Kiểm tra iptables/IPVS -> Dùng tcpdump tại interface ảo (veth) của Pod để xem packet đã vào đến "cửa" của container hay chưa.
Lộ trình Đọc
Phần 1: Phá vỡ rào cản nền tảng
Mục tiêu: Xây dựng lại tư duy hệ thống phân tán, từ bỏ thói quen vận hành máy chủ vật lý.
Bài 1: Từ Monolith đến Kubernetes – Bài toán Scale và Tư duy Container Orchestration
Bài 2: Mạng lưới Kubernetes – Phân tích Core Objects và luồng Traffic ở Packet Level
Phần 2: Sinh tồn trên môi trường Production
Mục tiêu: Đưa ứng dụng vào môi trường thực tế an toàn, tối ưu tài nguyên và không gián đoạn.
Bài 3: Bảo mật cấu hình Kubernetes – Quản lý Config & Secrets an toàn trên Production
Bài 4: Vận hành Kubernetes – Tối ưu Resource, Auto-Healing và Scale Zero-Downtime
Phần 3: Trưởng thành với tiêu chuẩn Enterprise
Mục tiêu: Nâng tầm kiến trúc, thiết lập phòng thủ chuyên sâu và tự động hóa vận hành.