
Trong giới kỹ sư hệ thống, chúng ta thường chia vòng đời của một dự án thành ba giai đoạn. Day-Zero là khâu thiết kế kiến trúc. Day-One là ngày triển khai hệ thống lên môi trường thực tế. Nhưng giai đoạn tàn khốc nhất và kéo dài nhất chính là Day-Two, thời điểm ứng dụng bắt đầu đón nhận hàng triệu lượt truy cập và đối mặt với vô vàn rủi ro không thể lường trước.
Khi cụm Kubernetes của bạn đã được bảo mật cấu hình, tối ưu tài nguyên và thiết lập tự phục hồi, câu hỏi đặt ra là làm sao để duy trì sự ổn định đó trong nhiều năm tiếp theo mà không bị phụ thuộc vào một cá nhân vận hành cụ thể nào.
Giám sát toàn diện hệ thống bằng các công cụ đo lường và quản lý nhật ký tập trung
Một trong những đặc điểm nổi bật nhất của Kubernetes là tính phù du của các Pod. Một vùng chứa có thể được sinh ra ở máy chủ này và chết đi chỉ vài phút sau đó để nhường chỗ cho vùng chứa khác. Nếu bạn vẫn giữ thói quen SSH vào máy chủ vật lý để đọc file log như thời dùng kiến trúc nguyên khối, bạn sẽ hoàn toàn mù màu trước các sự cố. Khi Pod biến mất, toàn bộ dữ liệu nhật ký bên trong nó cũng bốc hơi theo.
Để tồn tại ở giai đoạn Day-Two, hệ thống của bạn bắt buộc phải có tính quan sát toàn diện (Observability). Hệ sinh thái Cloud Native giải quyết bài toán này bằng bộ ba công cụ kinh điển.
Đầu tiên, hệ thống cần một cỗ máy thu thập dữ liệu đo lường theo thời gian thực (Metrics). Prometheus là tiêu chuẩn vàng cho nhiệm vụ này, nó liên tục quét và kéo dữ liệu về mức tiêu thụ CPU, RAM, hay số lượng kết nối HTTP từ tất cả các Node và Pod.
Dữ liệu thô từ Prometheus sau đó sẽ được đổ lên Grafana để trực quan hóa thành các biểu đồ bảng điều khiển, giúp quản trị viên nắm bắt sức khỏe hệ thống chỉ bằng một cái liếc mắt.
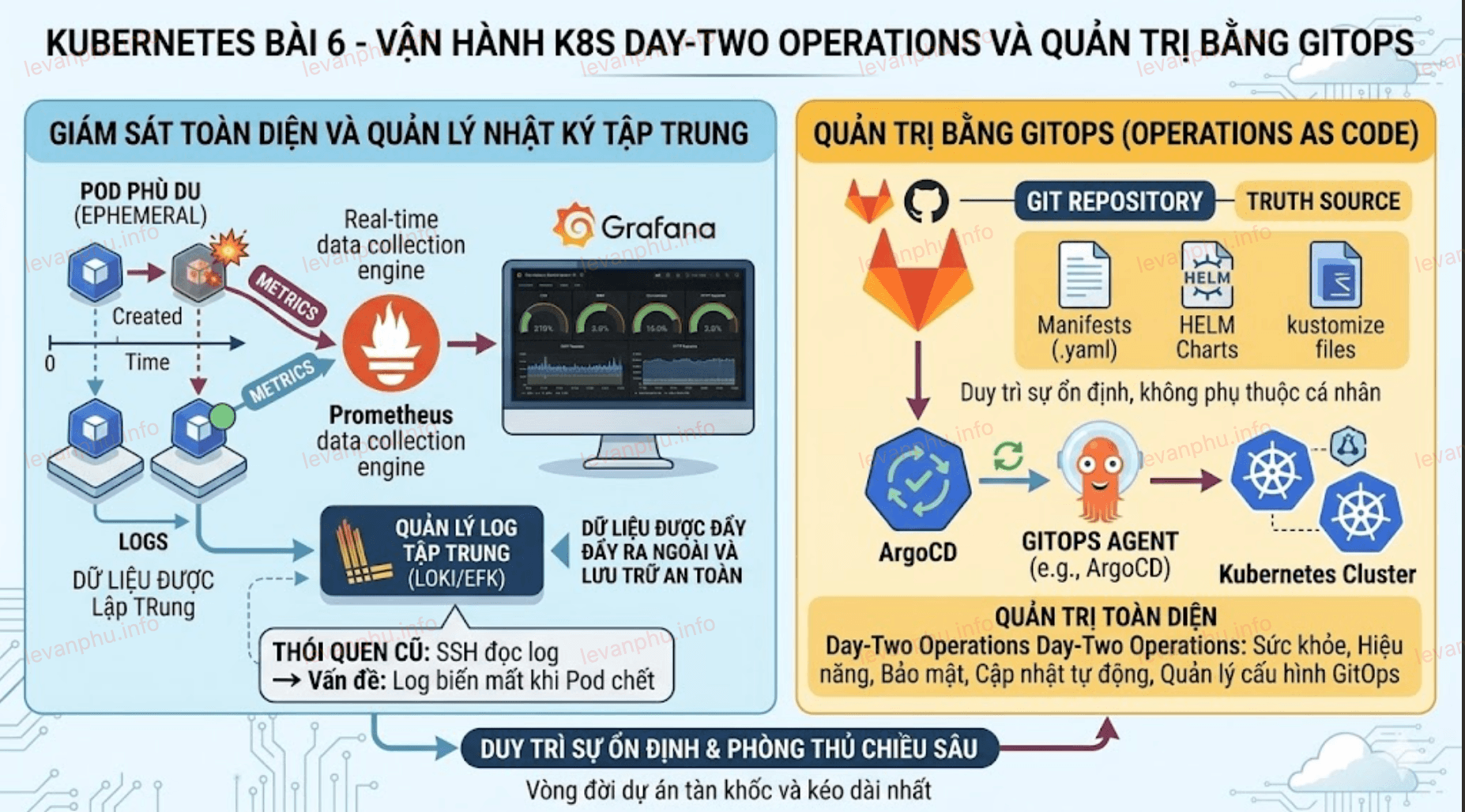
Cuối cùng, để giải quyết bài toán nhật ký bị mất, chúng ta triển khai các giải pháp quản lý log tập trung như Loki hoặc ngăn xếp EFK (Elasticsearch, Fluentd, Kibana). Toàn bộ log của ứng dụng sẽ được đẩy ra ngoài và lưu trữ an toàn ngay cả khi ứng dụng đã sụp đổ.
Phân biệt rõ Day 0 / Day 1 / Day 2 Operations
Đây là phần rất quan trọng để người đọc hiểu vị trí của GitOps trong vòng đời Kubernetes.
| Giai đoạn | Ý nghĩa |
|---|---|
| Day 0 | Thiết kế kiến trúc cluster, network, security baseline |
| Day 1 | Triển khai cluster và application ban đầu |
| Day 2 | Vận hành liên tục: scaling, patching, backup, observability, policy, DR, cost optimization |
GitOps chủ yếu nằm ở Day 2 Operations, nơi hệ thống cần:
- Drift detection
- Automated reconciliation
- Rollback
- Audit trail
- Multi-environment consistency
GitOps vận hành dựa trên việc Git là “single source of truth”.
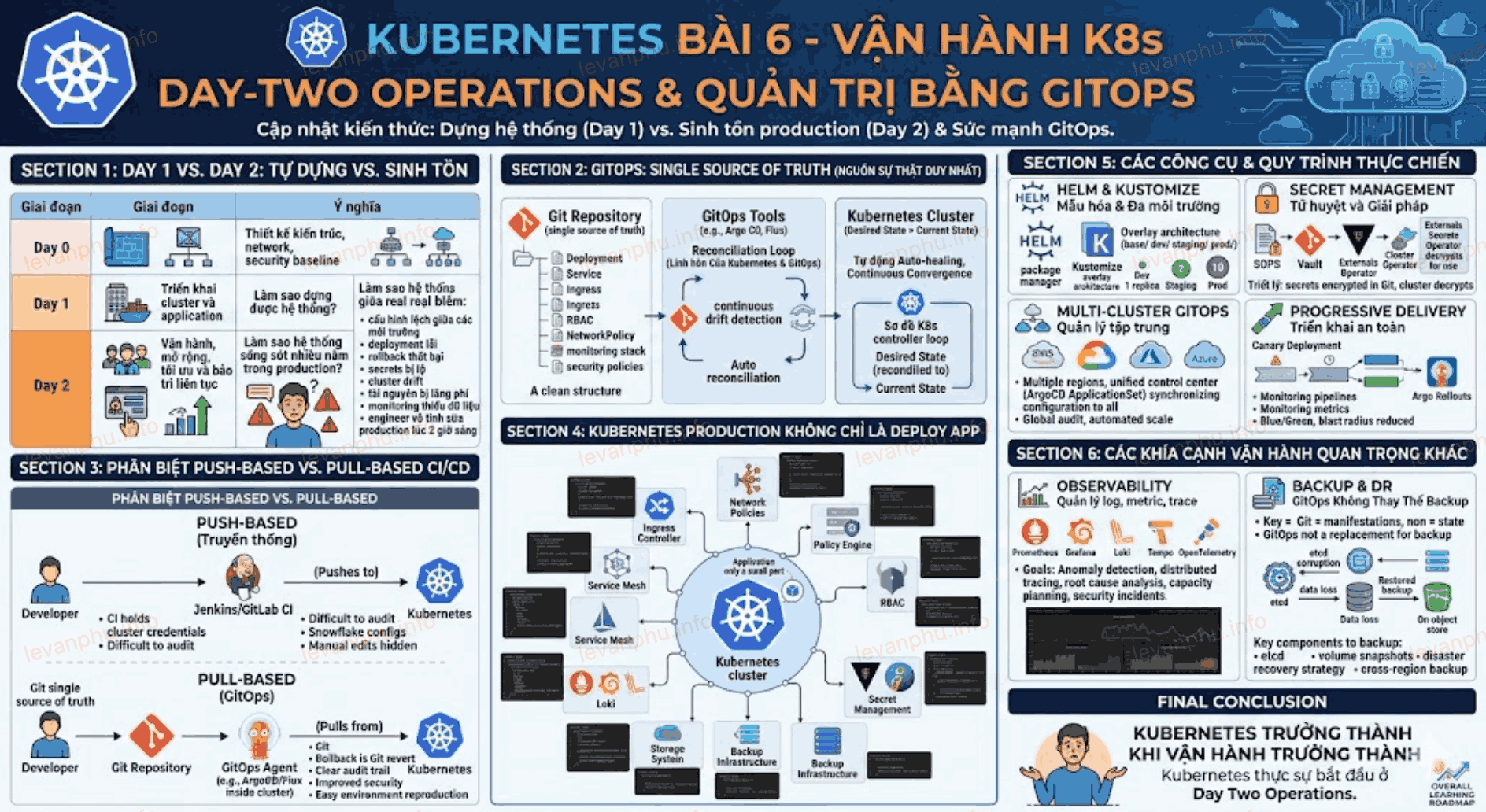
Thay đổi tư duy vận hành và đồng bộ hạ tầng tự động qua phương pháp GitOps
Khi quản lý hệ thống lớn, việc để các kỹ sư tự do gõ các lệnh cập nhật hạ tầng trực tiếp trên môi trường Production là một rủi ro khổng lồ. Nó dẫn đến tình trạng trôi dạt cấu hình, nơi hệ thống thực tế chạy một kiểu nhưng tài liệu mô tả lại ghi một kiểu khác.
Khái niệm GitOps ra đời để chấm dứt sự hỗn loạn này. Đây là một sự chuyển dịch lớn về mặt tư duy, nơi kho lưu trữ mã nguồn Git (như GitHub hay GitLab) trở thành nguồn sự thật duy nhất cho toàn bộ cơ sở hạ tầng. Mọi thay đổi về cấu hình, dù là tăng số lượng bản sao ứng dụng hay cập nhật phiên bản mới, đều phải được thực hiện thông qua thao tác gộp mã (Pull Request) và có người phê duyệt rõ ràng.
Thay vì đẩy mã trực tiếp vào cụm Kubernetes, chúng ta sử dụng các công cụ triển khai theo cơ chế kéo (Pull-based) như ArgoCD hay FluxCD. Các công cụ này chạy bên trong hệ thống, liên tục theo dõi sự thay đổi trên kho Git. Khi phát hiện mã nguồn cấu hình vừa được cập nhật, ArgoCD sẽ tự động kéo bản cấu hình đó về và đồng bộ hóa trạng thái của cụm Kubernetes cho khớp với những gì được khai báo trên Git.
Dưới góc nhìn an toàn thông tin, GitOps là một bước tiến mang tính cách mạng. Nó cho phép thu hồi hoàn toàn quyền truy cập trực tiếp vào cụm máy chủ của tất cả kỹ sư. Không ai cần cầm chứng chỉ hay mật khẩu để kết nối vào Kubernetes nữa, mọi rủi ro lộ lọt thông tin xác thực quản trị viên đều bị triệt tiêu hoàn toàn.
Chiến lược mở rộng kiến trúc đa cụm và phân chia tài nguyên an toàn
Khi doanh nghiệp phát triển đến một quy mô nhất định, một cụm Kubernetes duy nhất sẽ không còn đủ sức gánh vác, hoặc rủi ro thảm họa (Blast Radius) trở nên quá lớn nếu hệ thống đó gặp sự cố. Quản trị viên Day-Two phải đối mặt với bài toán chia để trị thông qua thiết kế đa người thuê và kiến trúc đa cụm.
Với chiến lược đa người thuê (Multi-tenant) trên cùng một cụm máy chủ, rủi ro lớn nhất là sự lấn chiếm tài nguyên (Noisy Neighbor). Đội ngũ A có thể chạy các ứng dụng ngốn quá nhiều phần cứng, làm treo luôn hệ thống của đội ngũ B. Giải pháp là sử dụng Resource Quotas và Limit Ranges kết hợp cùng các ranh giới mạng đã thiết lập. Bằng cách chia nhỏ một hệ thống lớn thành các không gian tên (Namespaces) độc lập và cấp hạn mức sử dụng CPU tối đa cho từng không gian, chúng ta đảm bảo các đội dự án không bao giờ có thể giẫm chân lên nhau.
Đối với các hệ thống tài chính hoặc nền tảng dịch vụ trọng yếu, việc triển khai kiến trúc đa cụm (Multi-cluster) chạy trên các vùng địa lý hoặc các nhà cung cấp đám mây khác nhau là bắt buộc để đảm bảo tính sẵn sàng cao. Nếu toàn bộ trung tâm dữ liệu tại một khu vực bị mất điện, luồng truy cập của khách hàng ngay lập tức được hệ thống phân giải tên miền toàn cầu điều hướng sang cụm Kubernetes dự phòng ở khu vực khác mà dịch vụ không hề bị gián đoạn.
Truy vết sự cố và thiết lập hệ thống kiểm toán phục vụ điều tra an ninh
Là một chuyên gia bảo mật, nguyên tắc sống còn khi đối phó với sự cố là không bao giờ tin vào những gì bạn chưa nhìn thấy bằng chứng ghi nhận lại. Khi một hệ thống bị xâm nhập hoặc sụp đổ do cấu hình sai, điều đầu tiên đội phản ứng sự cố cần là một bản ghi chép chi tiết về tất cả những gì đã xảy ra.
Mặc định, Kubernetes xử lý hàng triệu lệnh gọi API mỗi ngày nhưng không lưu lại ai đã thực hiện lệnh đó. Nếu kẻ gian lọt được vào hệ thống và âm thầm thay đổi cấu hình mạng nội bộ, bạn sẽ không bao giờ biết được chúng đã làm điều đó lúc mấy giờ và dùng tài khoản nào.
Bật tính năng Audit Logging (Nhật ký kiểm toán) ở mức API Server là yêu cầu bắt buộc đối với hệ thống Production. Tính năng này ghi nhận lại toàn bộ siêu dữ liệu của mỗi yêu cầu gửi đến máy chủ điều khiển, bao gồm danh tính người dùng, địa chỉ IP gốc, hành động cụ thể và đối tượng bị tác động. Những nhật ký kiểm toán này phải được đẩy ngay ra một hệ thống lưu trữ bên ngoài không thể chỉnh sửa để bảo toàn bằng chứng số. Trong trường hợp thảm họa bảo mật xảy ra, dữ liệu từ Audit Logging chính là chiếc hộp đen vô giá giúp các chuyên gia an toàn thông tin điều tra số, dựng lại hiện trường và vá lỗ hổng để đảm bảo sự cố tương tự không lặp lại trong tương lai.
Lộ trình Đọc
Phần 1: Phá vỡ rào cản nền tảng
Mục tiêu: Xây dựng lại tư duy hệ thống phân tán, từ bỏ thói quen vận hành máy chủ vật lý.
Bài 1: Từ Monolith đến Kubernetes – Bài toán Scale và Tư duy Container Orchestration
Bài 2: Mạng lưới Kubernetes – Phân tích Core Objects và luồng Traffic ở Packet Level
Phần 2: Sinh tồn trên môi trường Production
Mục tiêu: Đưa ứng dụng vào môi trường thực tế an toàn, tối ưu tài nguyên và không gián đoạn.
Bài 3: Bảo mật cấu hình Kubernetes – Quản lý Config & Secrets an toàn trên Production
Bài 4: Vận hành Kubernetes – Tối ưu Resource, Auto-Healing và Scale Zero-Downtime
Phần 3: Trưởng thành với tiêu chuẩn Enterprise
Mục tiêu: Nâng tầm kiến trúc, thiết lập phòng thủ chuyên sâu và tự động hóa vận hành.