
Một hệ thống đã an toàn về mạng và bảo mật cấu hình vẫn có thể sụp đổ hoàn toàn nếu quản trị viên không biết cách dạy cho Kubernetes cách đối xử với ứng dụng. Nhiều kỹ sư lầm tưởng rằng chỉ cần ném ứng dụng vào Cluster là nó sẽ tự động sống mãi không chết. Thực tế, Kubernetes là một hệ thống mù mờ về business logic. Nó không biết ứng dụng của bạn đang chạy tốt hay đang bị treo nạp dữ liệu, trừ khi bạn chỉ định rõ ràng các quy tắc giám sát và giới hạn tài nguyên.
Bài viết này sẽ đi sâu vào các cơ chế ở tầng Kernel giúp hệ thống tự phục hồi, chống lại các đợt tấn công cạn kiệt tài nguyên và cập nhật phiên bản mới mà người dùng không hề hay biết.
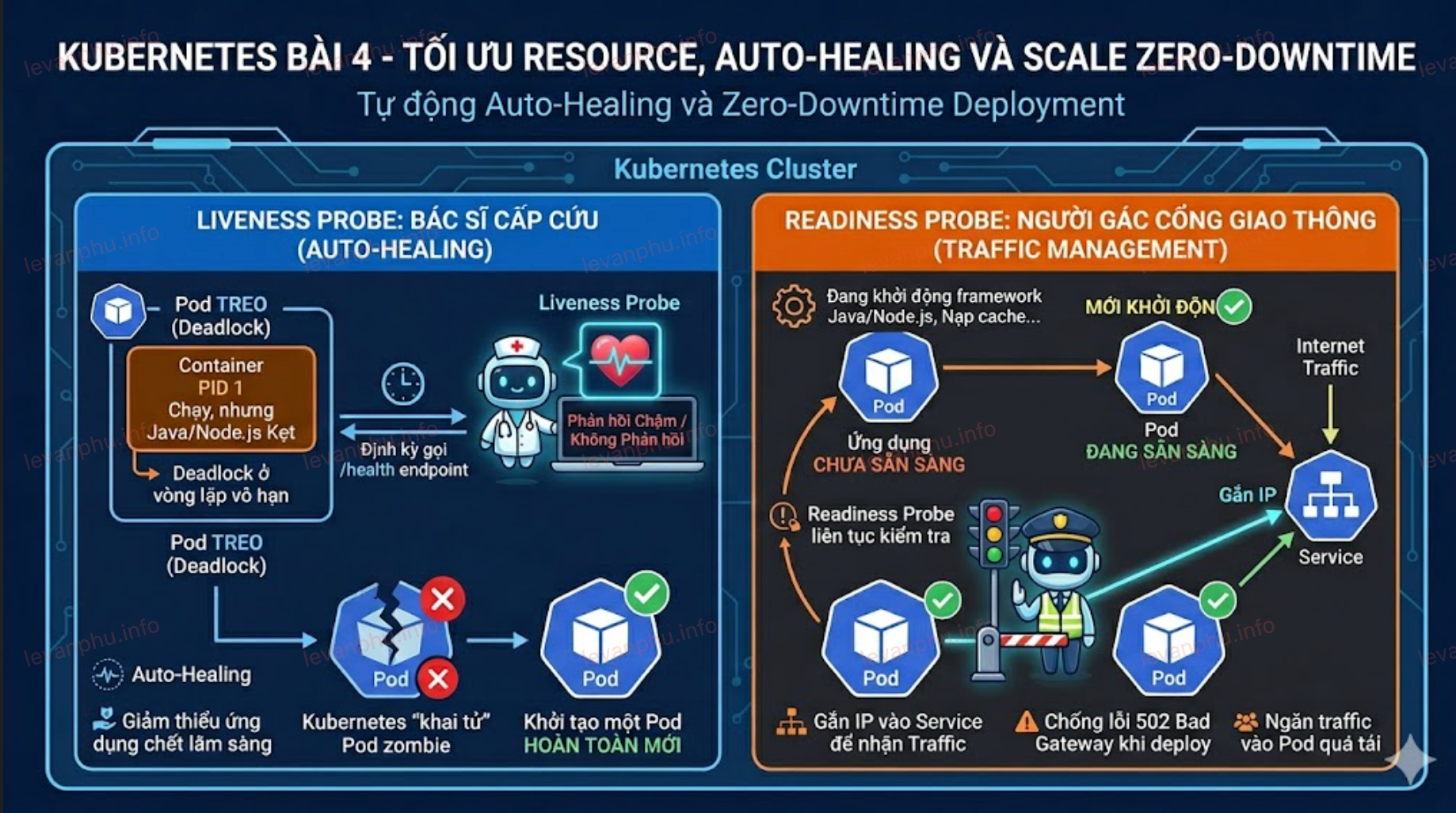
Tự động phục hồi ứng dụng bằng cơ chế Health Checks
Theo mặc định, Kubernetes chỉ đánh giá một container là đang sống nếu tiến trình (PID 1) của container đó vẫn đang chạy. Tuy nhiên trong thực tế vận hành, một ứng dụng Java hay Node.js có thể vẫn giữ PID 1 nhưng lại bị kẹt (deadlock) ở vòng lặp vô hạn hoặc mất kết nối hoàn toàn đến database khiến nó không thể phục vụ người dùng.
Để giải quyết bài toán này, chúng ta phải cấu hình các cơ chế thăm dò sức khỏe (Probes) ở tầng ứng dụng.
Liveness Probe đóng vai trò như một bác sĩ cấp cứu. Kubernetes sẽ định kỳ gọi vào một endpoint (ví dụ đường dẫn /health) của ứng dụng. Nếu ứng dụng không phản hồi sau một số lần nhất định, Kubernetes kết luận rằng Pod này đã rơi vào trạng thái zombie và sẽ lập tức "khai tử" nó để khởi tạo một Pod hoàn toàn mới. Đây chính là bản chất của cơ chế Auto-Healing.
Readiness Probe lại đóng vai trò như người gác cổng giao thông. Một Pod mới được tạo ra có thể mất vài chục giây để khởi động framework và nạp cache. Nếu Kubernetes vội vàng đẩy traffic của người dùng vào lúc này, họ sẽ nhận ngay lỗi 502 Bad Gateway. Readiness Probe sẽ liên tục kiểm tra, và chỉ khi ứng dụng thực sự báo cáo đã sẵn sàng, Pod mới được gắn IP vào Service để bắt đầu nhận lưu lượng mạng. Nếu ứng dụng quá tải, Readiness Probe sẽ tạm thời gỡ Pod đó ra khỏi Service để nó có thời gian thở.
Ngăn chặn thảm họa sập Node với Resource Requests và Limits
Dưới góc nhìn an toàn thông tin và độ ổn định hệ thống, việc không cấu hình giới hạn tài nguyên cho Pod là hành vi cực kỳ nguy hiểm. Nó tạo ra lỗ hổng cạn kiệt tài nguyên (Resource Exhaustion) hoặc vấn nạn láng giềng ồn ào (Noisy Neighbor).
Nếu một hacker khai thác thành công lỗi ReDoS (Regular Expression Denial of Service) trên một API không giới hạn tài nguyên, tiến trình đó sẽ nuốt trọn 100% CPU và RAM của toàn bộ Worker Node vật lý. Hệ quả là tất cả các ứng dụng khác chạy chung trên Node đó đều bị kéo sập theo.
Kubernetes giải quyết triệt để vấn đề này thông qua cơ chế cgroups của nhân Linux bằng hai thông số Requests và Limits.
Requests là lượng tài nguyên tối thiểu hệ thống cam kết đặt cọc cho Pod. Kube-scheduler dựa vào con số này để tìm kiếm và quyết định xếp Pod lên Worker Node nào có đủ không gian trống.
Limits là ranh giới tử thần. Khi bạn cấu hình giới hạn RAM, nếu ứng dụng bị rò rỉ bộ nhớ (Memory Leak) và phình to vượt qua mức Limit, Linux Kernel sẽ ngay lập tức kích hoạt OOMKilled (Out Of Memory Killed) để tiêu diệt tiến trình, bảo vệ an toàn cho Node. Đối với CPU, khi ứng dụng cố gắng vượt quá Limit, nó không bị giết chết nhưng sẽ bị ép xung (CPU Throttling) khiến ứng dụng chạy chậm lại.
Mở rộng hệ thống linh hoạt dựa trên tải thực tế
Khi lượng truy cập tăng vọt trong các đợt flash sale hoặc chiến dịch marketing, việc tăng số lượng Pod thủ công không bao giờ đáp ứng kịp thời gian thực. Cơ chế Horizontal Pod Autoscaler (HPA) ra đời để tự động hóa hoàn toàn quy trình này.
HPA hoạt động bằng cách liên tục giao tiếp với Metrics Server để thu thập dữ liệu tiêu thụ CPU và RAM của từng Pod. Quản trị viên chỉ cần khai báo một ngưỡng mục tiêu, ví dụ muốn duy trì mức sử dụng CPU trung bình ở mức 70%.
Khi lượng traffic đổ về làm CPU của các Pod hiện tại vượt quá 70%, vòng lặp đồng bộ của Kubernetes sẽ tính toán thuật toán và tự động tăng số lượng bản sao (Replicas) lên. Các Pod mới ngay lập tức chia sẻ gánh nặng với các Pod cũ. Ngược lại, khi đêm xuống và lưu lượng giảm, HPA sẽ từ từ dọn dẹp và thu hồi các Pod thừa thãi để tiết kiệm chi phí hạ tầng máy chủ.
Triển khai phiên bản mới mượt mà không gây gián đoạn dịch vụ
Nỗi ám ảnh lớn nhất của các đội ngũ vận hành hệ thống truyền thống là thời gian downtime khi cập nhật phiên bản mới (Deployment). Các kỹ sư thường phải canh lịch bảo trì lúc nửa đêm để khách hàng ít bị ảnh hưởng nhất.
Trong Kubernetes, chiến lược Rolling Update mặc định biến quá trình này thành một nghệ thuật không gián đoạn (Zero-Downtime). Thay vì tắt toàn bộ hệ thống cũ đi rồi mới bật hệ thống mới lên, Kubernetes thực hiện việc thay máu một cách từ từ dựa trên hai thông số kiểm soát là MaxSurge và MaxUnavailable.
Hệ thống sẽ khởi tạo một vài Pod của phiên bản mới. Tại thời điểm này, cơ chế Readiness Probe (như đã phân tích ở trên) sẽ giám sát chặt chẽ. Chỉ khi Pod mới báo cáo đã khởi động thành công và sẵn sàng nhận traffic, Kubernetes mới bắt đầu điều hướng người dùng sang đó, đồng thời xóa đi một Pod của phiên bản cũ. Quá trình này lặp lại cuốn chiếu cho đến khi toàn bộ ứng dụng được cập nhật hoàn tất. Nếu trong quá trình nâng cấp phát hiện phiên bản mới bị lỗi (ví dụ CrashLoopBackOff), quá trình Rollout sẽ tự động dừng lại, đảm bảo hệ thống cũ vẫn tiếp tục phục vụ người dùng mà không gây ra bất kỳ sự cố diện rộng nào.
Lộ trình Đọc
Phần 1: Phá vỡ rào cản nền tảng
Mục tiêu: Xây dựng lại tư duy hệ thống phân tán, từ bỏ thói quen vận hành máy chủ vật lý.
Bài 1: Từ Monolith đến Kubernetes – Bài toán Scale và Tư duy Container Orchestration
Bài 2: Mạng lưới Kubernetes – Phân tích Core Objects và luồng Traffic ở Packet Level
Phần 2: Sinh tồn trên môi trường Production
Mục tiêu: Đưa ứng dụng vào môi trường thực tế an toàn, tối ưu tài nguyên và không gián đoạn.
Bài 3: Bảo mật cấu hình Kubernetes – Quản lý Config & Secrets an toàn trên Production
Bài 4: Vận hành Kubernetes – Tối ưu Resource, Auto-Healing và Scale Zero-Downtime
Phần 3: Trưởng thành với tiêu chuẩn Enterprise
Mục tiêu: Nâng tầm kiến trúc, thiết lập phòng thủ chuyên sâu và tự động hóa vận hành.