
Ngày 20 tháng 2: Thêm tính năng hỗ trợ cho các biến thể sản phẩm
Nội dung của Thêm tính năng hỗ trợ cho các biến thể sản phẩm
Các sản phẩm ngành may mặc, giày dép, đồ nội thất và thiết bị điện tử thường được bán với nhiều kiểu dáng, màu sắc, kích cỡ, chất liệu, họa tiết hoa văn... khác nhau. Mỗi sản phẩm có các đặc điểm khác nhau như vậy gọi là một biến thể sản phẩm.
Vậy nên để giúp Google hiểu rõ hơn những sản phẩm nào là phiên bản biến thể của cùng một sản phẩm gốc, ngoài sử dụng dữ liệu có cấu trúc Product, hãy sử dụng class ProductGroup với các thuộc tính liên quan như variesBy, hasVariant và ProductGroupID để nhóm các biến thể đó lại với nhau.
ProductGroup cũng cho phép bạn chỉ định các thuộc tính sản phẩm chung cho tất cả các biến thể, chẳng hạn như thông tin về thương hiệu và đánh giá, cũng như các thuộc tính để xác định biến thể như màu sắc, kích cỡ,... Điều này sẽ có thể làm giảm sự trùng lặp thông tin.
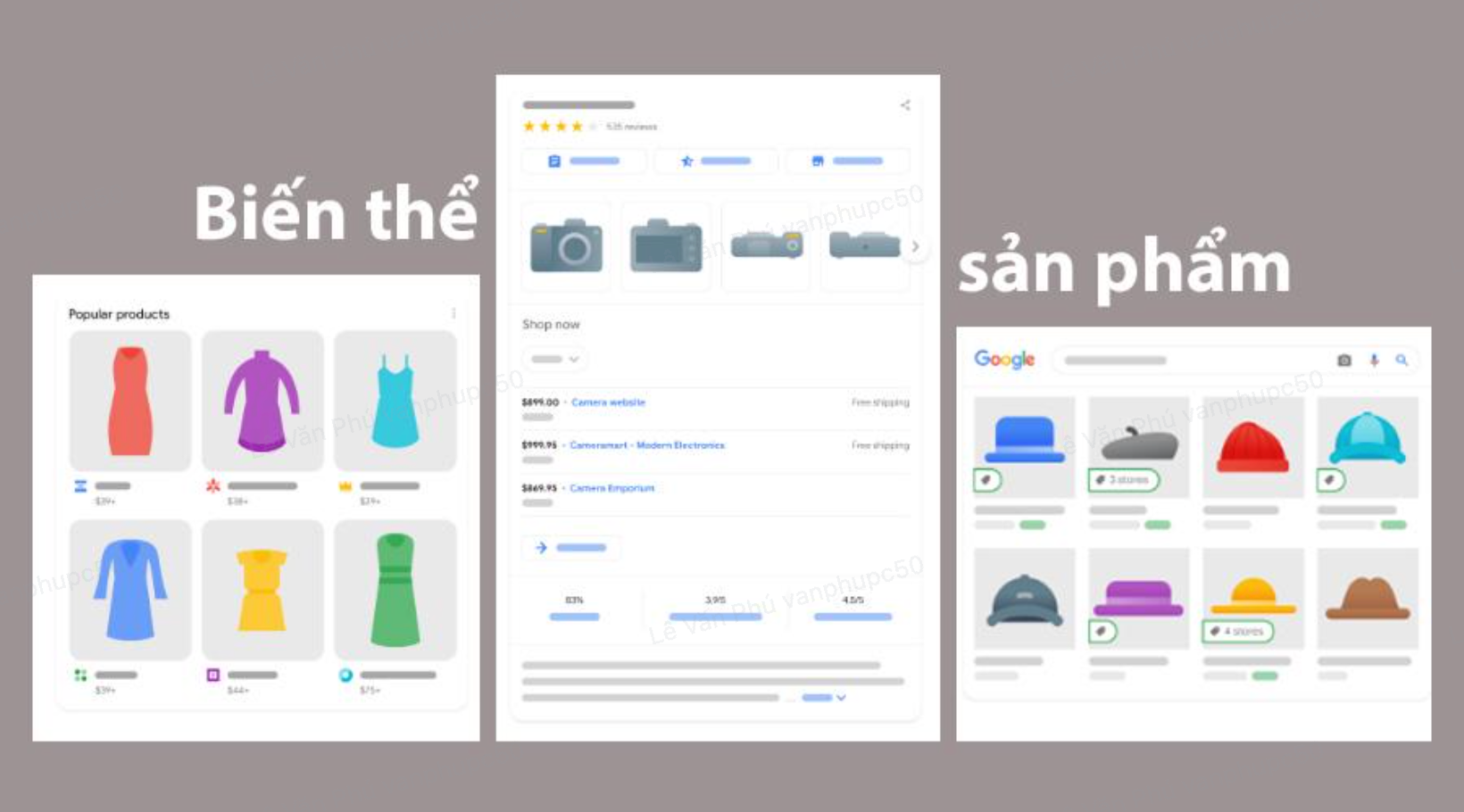
Thêm tài liệu mới về dữ liệu có cấu trúc cho biến thể sản phẩm. Ngoài ra, Google cũng thêm một thuộc tính isVariantof mới vào tài liệu về dữ liệu có cấu trúc cho sản phẩm và làm rõ rằng Google hỗ trợ các biến thể sản phẩm có URL riêng biệt.
Về dữ liệu có cấu trúc cho biến thể sản phẩm: Khi bạn thêm dữ liệu có cấu trúc vào các trang sản phẩm của mình, kết quả trên Google Tìm kiếm (bao gồm cả Google Hình ảnh và Google Lens) có thể hiển thị thông tin sản phẩm theo những cách phong phú hơn. Người dùng có thể xem giá, tình trạng còn hàng, xếp hạng đánh giá, thông tin giao hàng, v.v. ngay trong kết quả tìm kiếm.
Về cách Google hiểu URLs riêng biệt của các biến thể sản phẩm:
- Đối với các trang web thương mại điện tử: thường phải quan tâm đến cách tạo cấu trúc cho URL khi sản phẩm có nhiều kích thước hoặc màu sắc.
- Đối với Google: Mỗi tổ hợp thuộc tính sản phẩm được gọi là một biến thể sản phẩm. Google hỗ trợ nhiều cấu trúc URL cho các biến thể sản phẩm.
Vậy nên để giúp Google hiểu rõ biến thể sản phẩm của bạn, hãy chắc chắn rằng mỗi biến thể sẽ có URL riêng biệt. Google đề xuất nên sử dụng cấu trúc URL như sau:
Ví dụ bạn đang bán áo thun, thì bạn có thể sử dụng:
- Một phân đoạn đường dẫn (path segment), chẳng hạn như /aothun/xanhla
- Một tham số truy vấn (query parameter), chẳng hạn như /aothun?mausac=xanhla
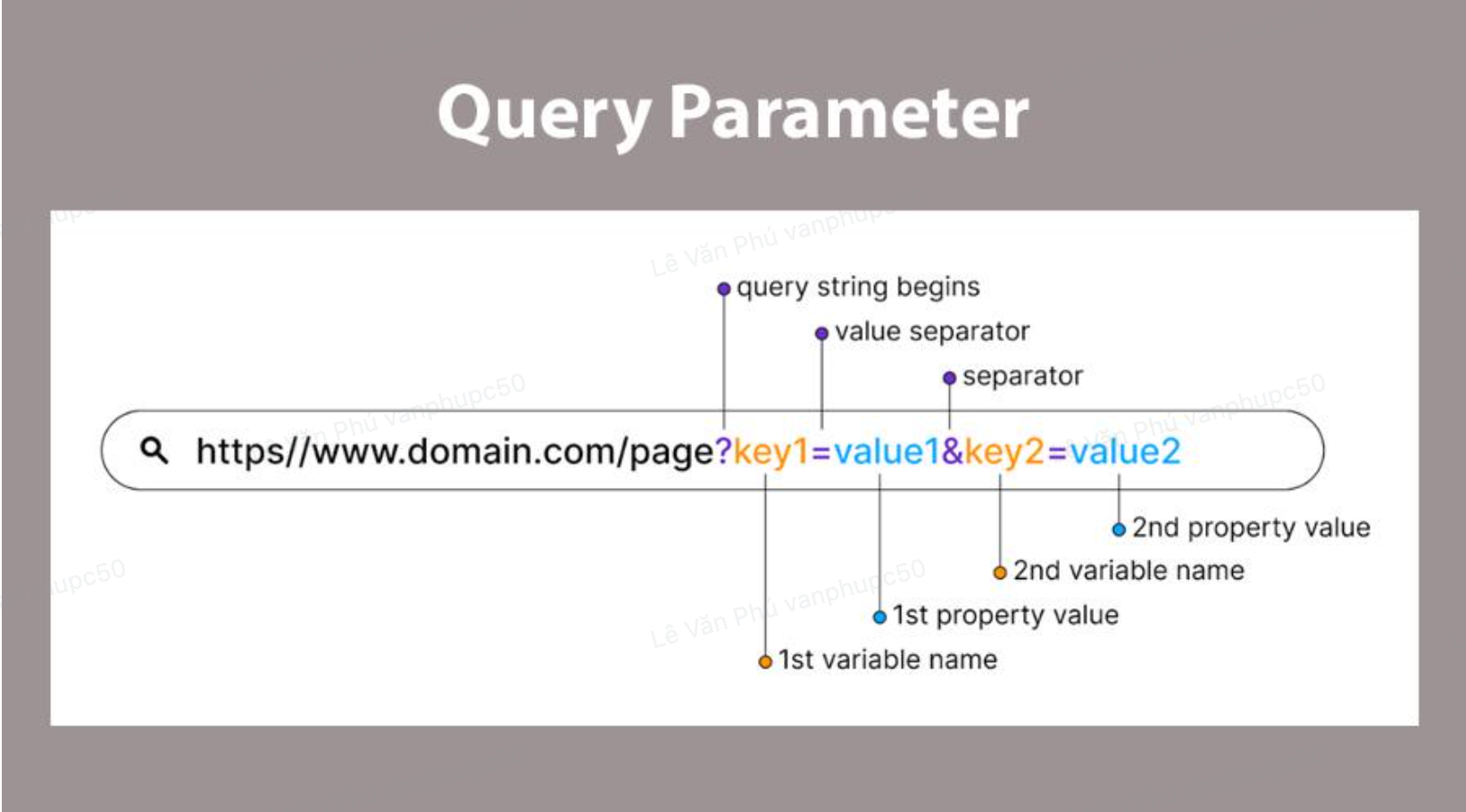
Một mẹo nhỏ dành cho bạn đó là nếu sử dụng các tham số truy vấn tuỳ chọn để xác định các biến thể, hãy sử dụng URL không có tham số truy vấn làm URL chính tắc (canonical URL). Cách này có thể giúp Google hiểu rõ hơn về mối quan hệ giữa các biến thể sản phẩm. Ví dụ: nếu giá trị mặc định của tham số truy vấn mausac cho áo thun là xanhduong, thì:
- Hãy dùng /aothun làm URL chính tắc (canonical URL) cho mọi loại áo thun
- Đối với áo sơ mi màu xanh dương, hãy dùng /aothun (chứ không phải /aothun?mausac=xanhduong)
- Đối với áo sơ mi màu xanh lá, hãy dùng /aothun?mausac=xanhla

Lý do của Thêm tính năng hỗ trợ cho các biến thể sản phẩm
Để hỗ trợ hiệu quả hơn cho những trường hợp liên quan đến biến thể sản phẩm cho trang web thương mại điện tử. Vì biến thể sản phẩm có thể là một khái niệm phức tạp và quan trọng đối với các trang web thương mại điện tử (đặc biệt là đối với những danh mục như quần áo và đồ điện tử).
Google sẽ cung cấp thêm ví dụ và hướng dẫn về cách thêm dữ liệu có cấu trúc cho biến thể sản phẩm vào những lần cập nhật sau.
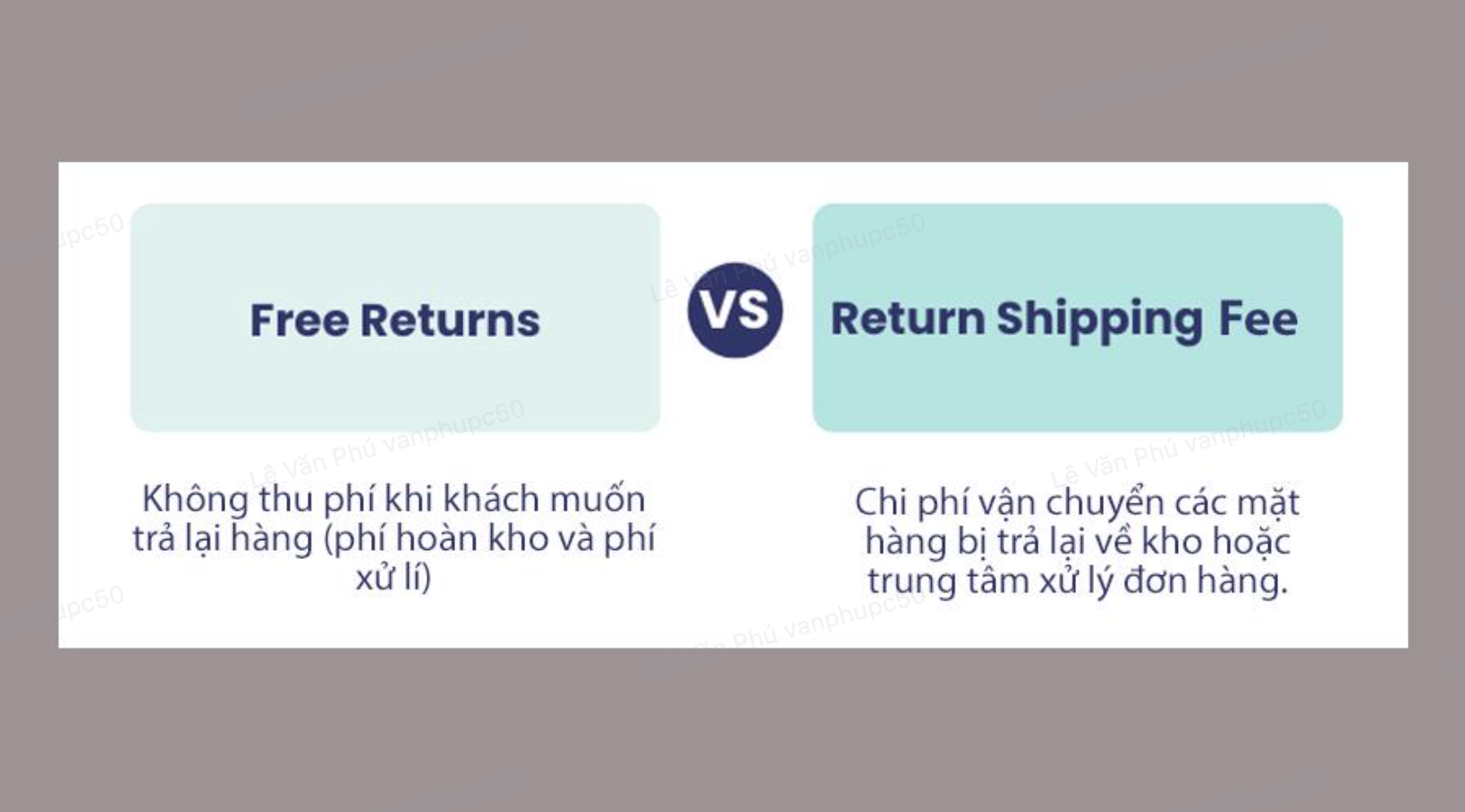
Làm rõ mã đánh dấu phí trả lại hàng cho sản phẩm
Nội dung của Làm rõ mã đánh dấu phí trả lại hàng cho sản phẩm
Làm rõ khi nào sử dụng FreeReturn so với ReturnShippingFees trong trường hợp chúng được tính vào giá trị cho returnFees khi sản phẩm được trả lại trong tài liệu về dữ liệu có cấu trúc cho sản phẩm
Lý do của Làm rõ mã đánh dấu phí trả lại hàng cho sản phẩm
Để hỗ trợ cho những trường hợp cần thông tin chi tiết hơn về phí vận chuyển và phí trả lại hàng.
Ngày 15 tháng 2: Làm rõ việc trích xuất chú thích rel="canonical"
Làm rõ rằng các chú thích rel="canonical" chứa một số thuộc tính nhất định không được dùng cho việc chuẩn hoá.
Về sử dụng chú thích link rel="canonical", bạn có thể đưa ra theo 2 cách (không nên dùng cả 2 vì dễ xảy ra lỗi):
Cách 1: Phần tử link rel="canonical" trong HTML
Giả sử bạn muốn chọn https://vidu.com/aothun/aothun-tayngan làm URL chính tắc, dù có nhiều URL có thể truy cập vào cùng nội dung. Hãy chỉ định URL này làm URL chính tắc qua những bước sau:
- Thêm phần tử
<link>có thuộc tínhrel="canonical"vào phần<head>của các trang trùng lặp để trỏ đến trang chính tắc. Ví dụ:
<html>
<head>
<title>CÔNG TY TNHH TMĐT CÔNG NGHỆ LP</title>
<link rel="canonical" href="https://lptech.asia/san-pham/anthun-tayngan" />
<!-- other elements -->
</head>
<!-- rest of the HTML -->- Nếu trang chính tắc có biến thể dành cho thiết bị di động trên một URL riêng, hãy thêm phần tử
linkrel="alternate"vào đó để trỏ đến phiên bản trang dành cho thiết bị di động:
<html>
<head>
<title>CÔNG TY TNHH TMĐT CÔNG NGHỆ LP</title>
<link rel="alternate" media="only screen and (max-width: 640px)" href="https://mobile.lptech.asia/san-pham/anthun-tayngan">
<link rel="canonical" href="https://aothunvip.com/aothun/anthun-tayngan" />
<!-- other elements -->
</head>
<!-- rest of the HTML -->- Thêm
hreflanghoặc phần tử bất kỳ nào khác phù hợp với trang.
Cách 2: Sử dụng header HTTP rel="canonical"
Nếu có thể thay đổi cấu hình của máy chủ, bạn có thể sử dụng header HTTP rel="canonical" thay vì phần tử HTML để chỉ định URL chính tắc cho một tài liệu được Google Search hỗ trợ, bao gồm cả tài liệu không phải HTML như tệp PDF.
Hiện Google chỉ hỗ trợ phương thức này cho các kết quả tìm kiếm trang web.
Lý do
Các chú thích rel="canonical" giúp Google xác định URL nào trong một tập hợp các trang trùng lặp là URL chính tắc. Việc thêm một số thuộc tính nhất định vào phần tử link sẽ thay đổi ý nghĩa của chú thích để biểu thị một phiên bản ngôn ngữ hoặc thiết bị khác.
Đây chỉ là thay đổi về tài liệu, nên nhớ Google luôn bỏ qua các chú thích rel="canonical" này khi chỉ định phiên bản chính tắc.
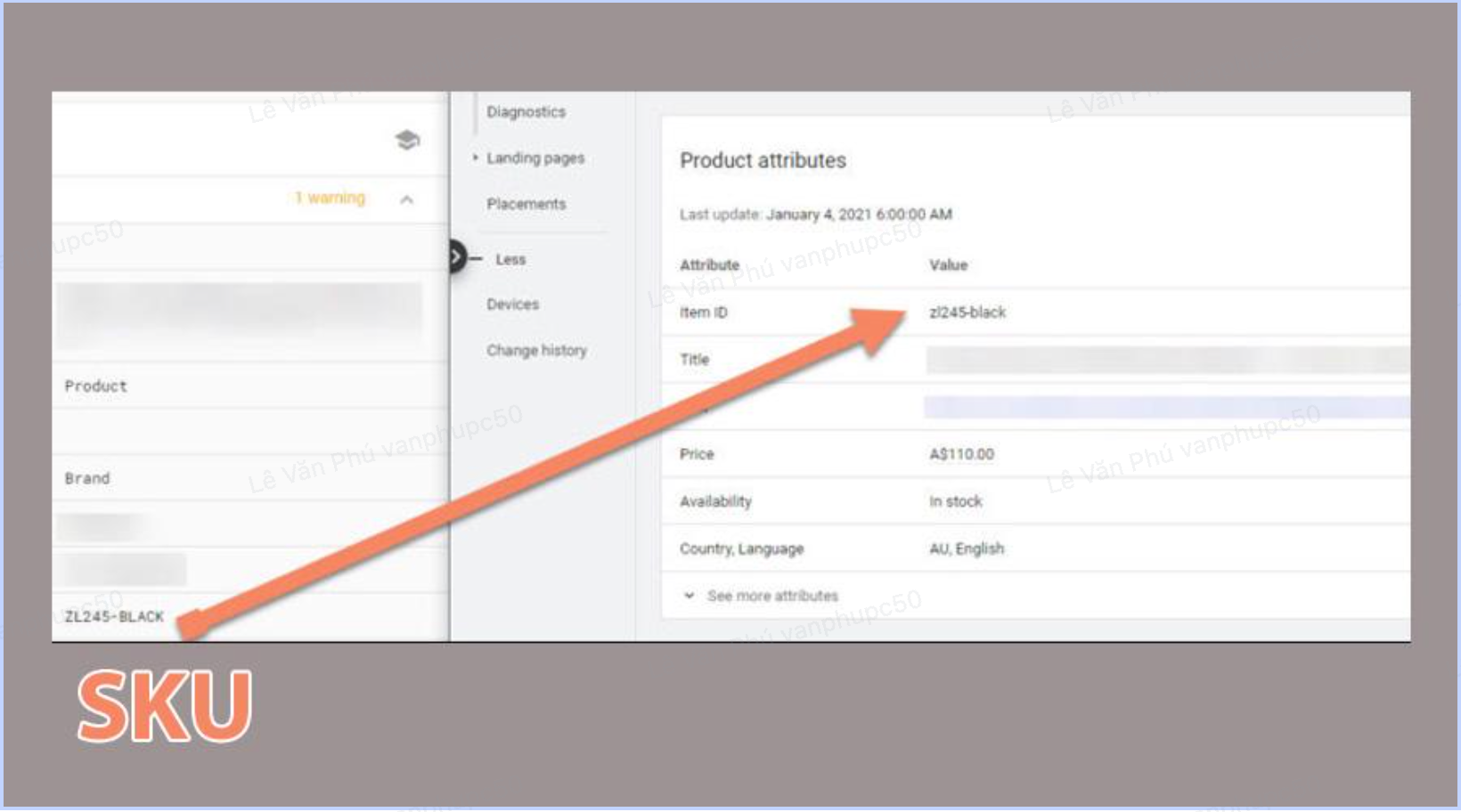
Ngày 9 tháng 2: Làm rõ việc sử dụng dấu cách trong SKUs (mã hàng hóa) sản phẩm
Nội dung của Làm rõ việc sử dụng dấu cách trong SKU sản phẩm
Làm rõ những ký tự được phép sử dụng trong SKU sản phẩm trong tài liệu về dữ liệu có cấu trúc cho Sản phẩm.
Lý do của Làm rõ việc sử dụng dấu cách trong SKU sản phẩm
Để giải thích rõ hơn lý do khiến giá trị sku có thể không hợp lệ trong công cụ Kiểm tra kết quả nhiều định dạng (Rich Results Test).
Làm mới tài liệu về việc xoá hình ảnh
Nội dung của Làm mới tài liệu về việc xoá hình ảnh
Google đã cập nhật tài liệu về việc xoá hình ảnh sao cho chính xác hơn, đồng thời giải quyết một số ý kiến phản hồi về tài liệu của họ.
Về việc xóa hình ảnh xuất hiện trong kết quả tìm kiếm
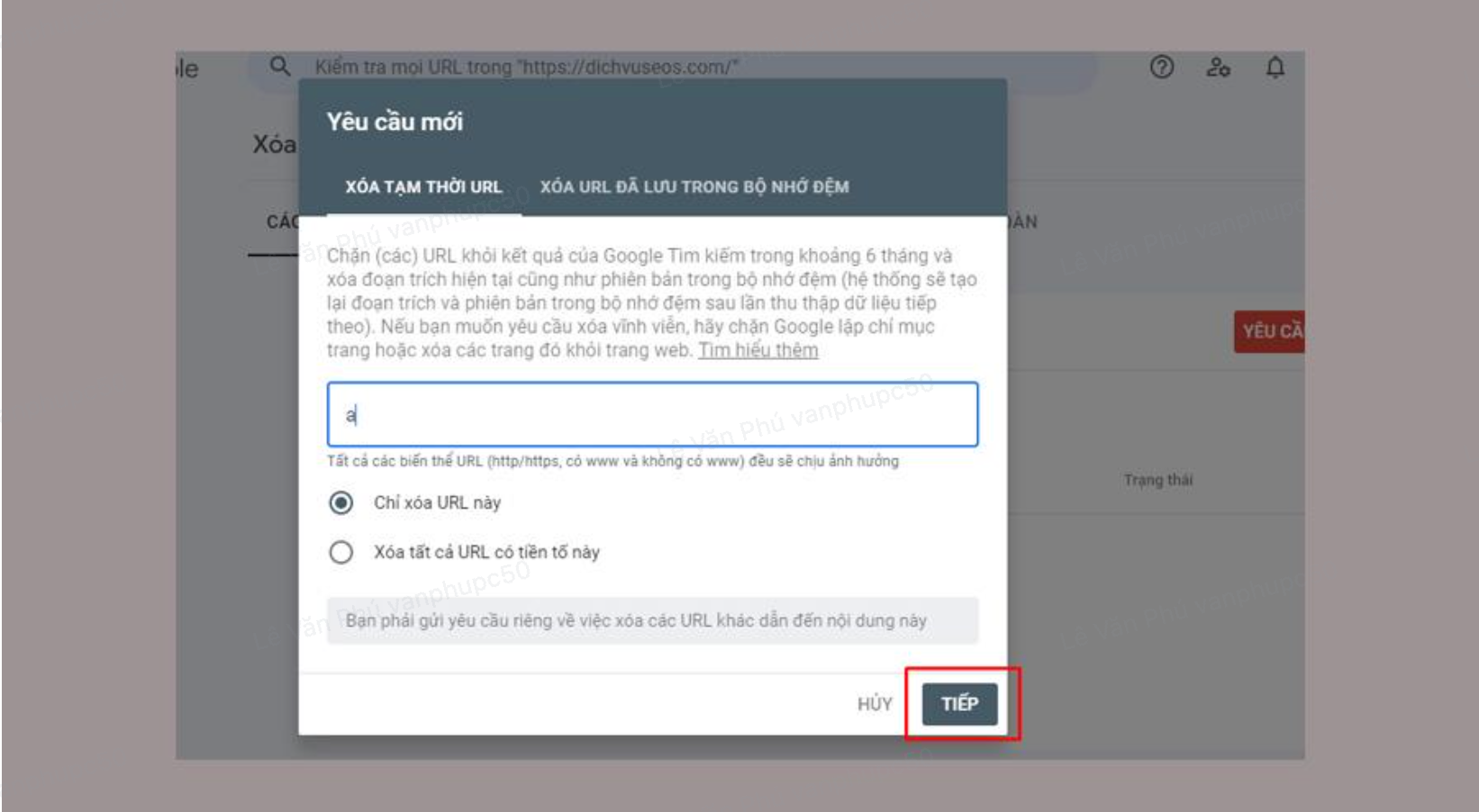
Trường hợp khẩn cấp thực hiện ngay bằng công cụ trong Google Search Console. Sử dụng công cụ xoá cho phép bạn tạm thời chặn các trang thuộc những trang web mà bạn sở hữu xuất hiện trên kết quả của Google Tìm kiếm và URL phải thuộc một tài sản mà bạn sở hữu trong Search Console.
Mở Công cụ xóa
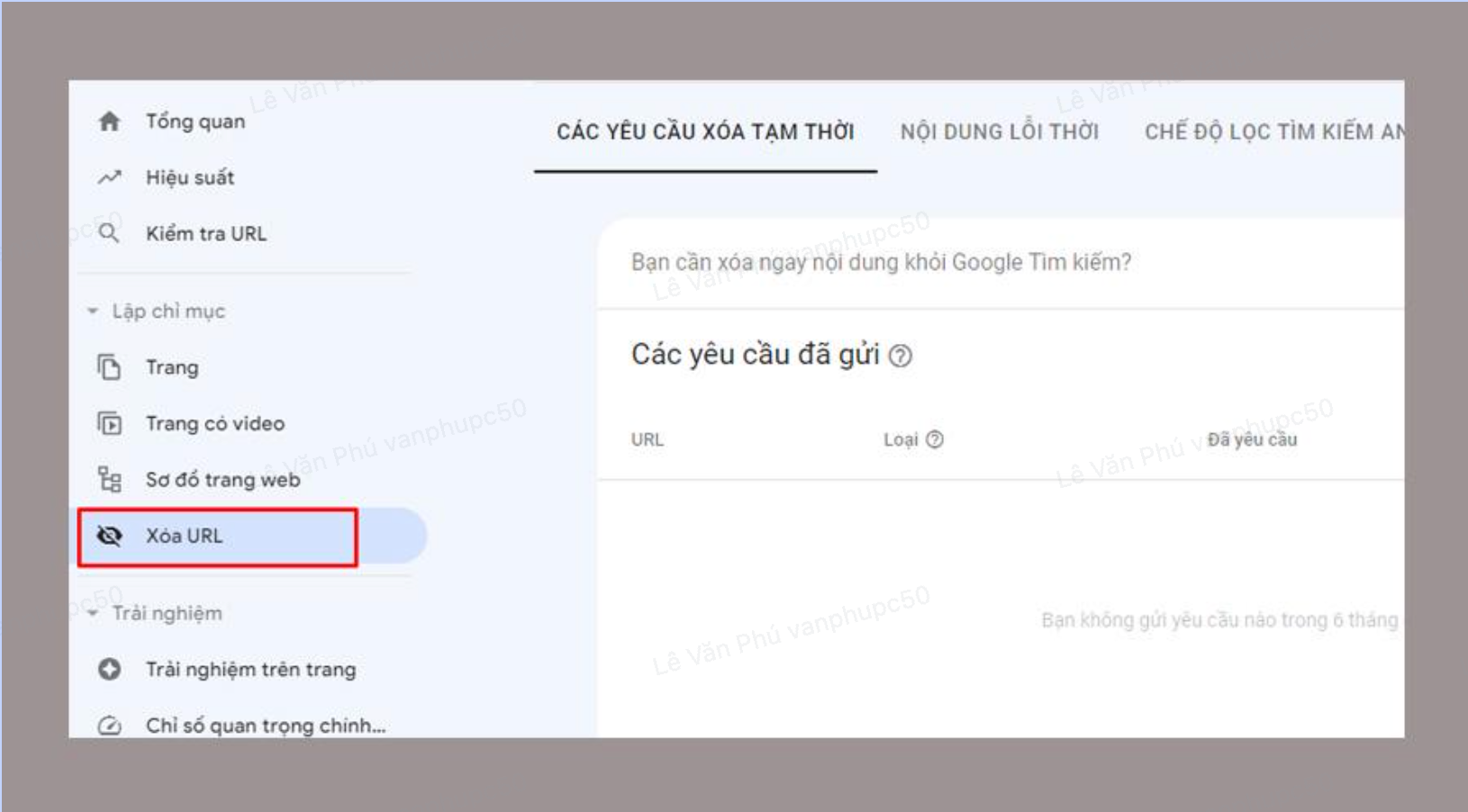
Chọn thẻ Các yêu cầu xoá tạm thời.
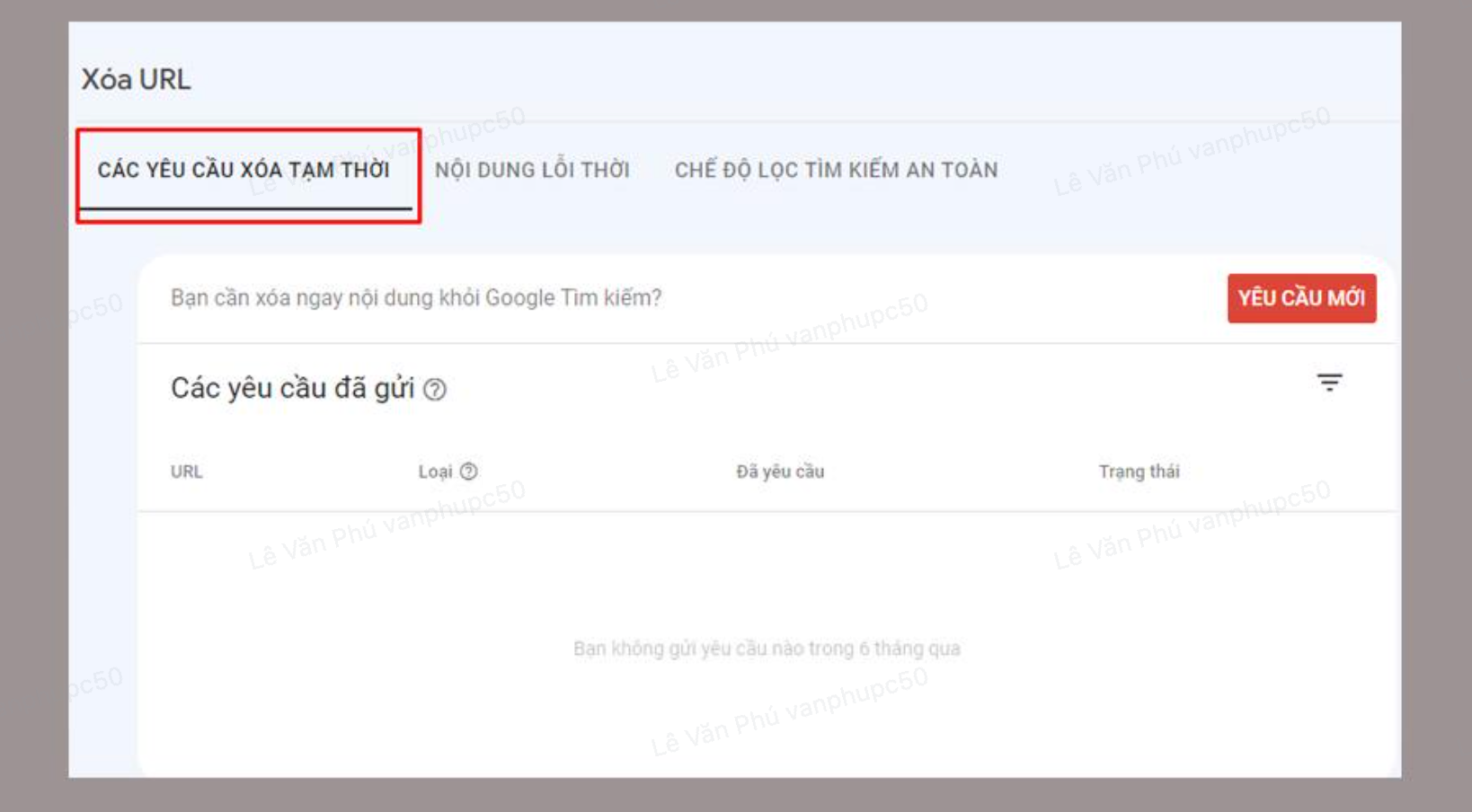
Nhấp vào Yêu cầu mới
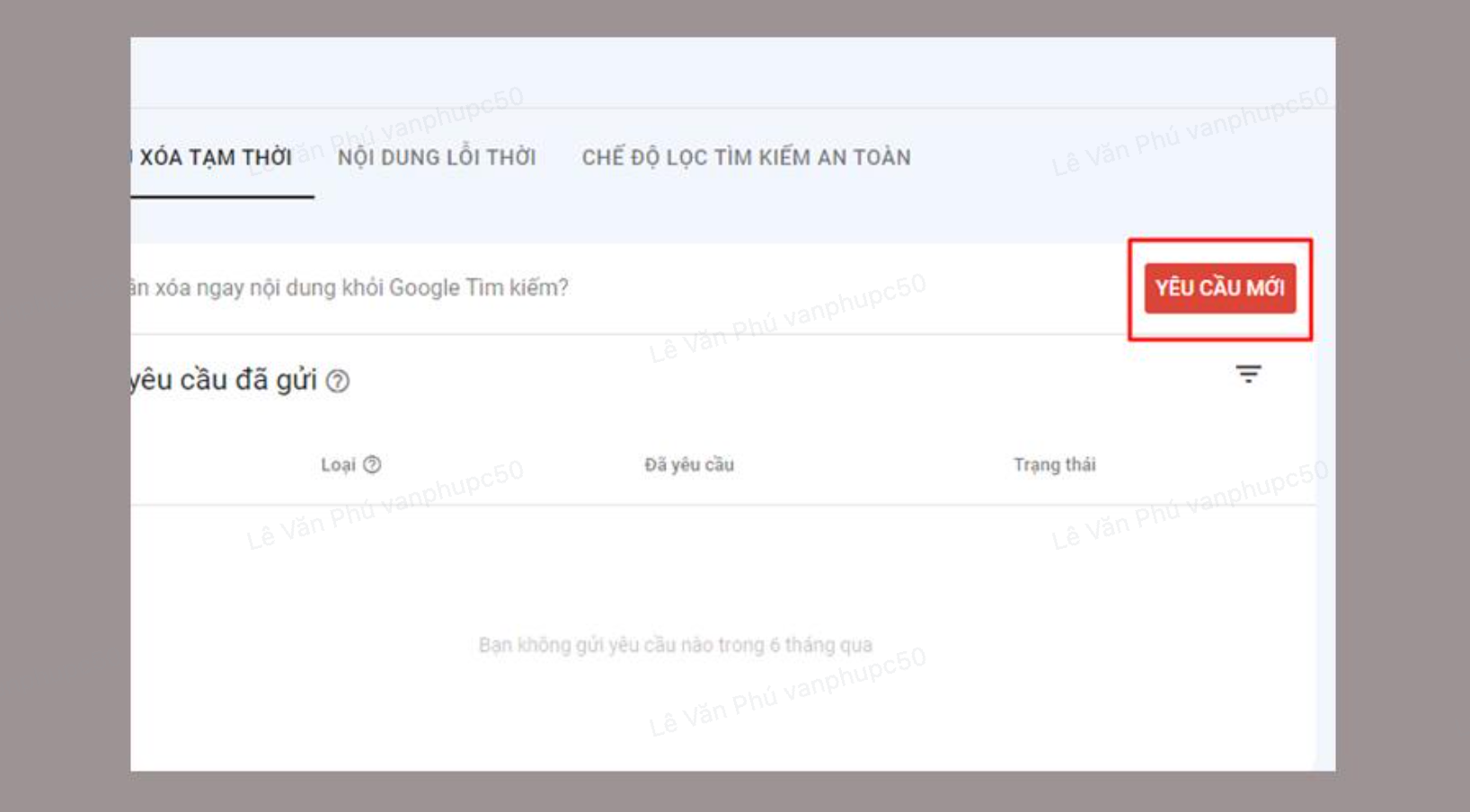
Chọn Xoá tạm thời URL hoặc Xoá URL đã lưu trong bộ nhớ đệm
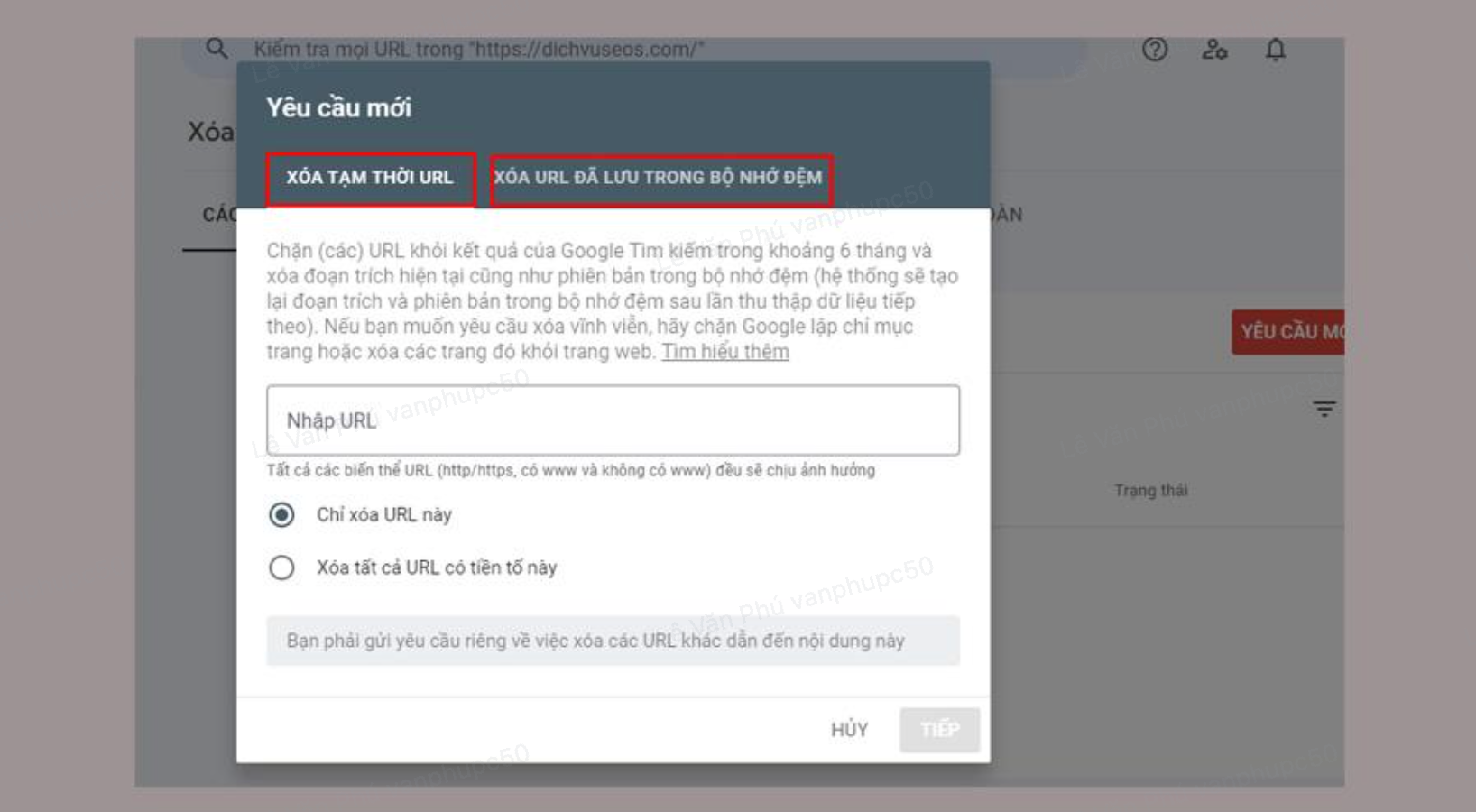
Chọn Tiếp theo để hoàn tất quy trình
Trường hợp không khẩn cấp bạn có hai cách để xoá hình ảnh trên trang web khỏi kết quả tìm kiếm trên Google trong trường hợp không gấp:
Cách 1: Xóa hình ảnh bằng quy tắc disallow trong tệp robots.txt
Thêm tệp robots.txt vào thư mục gốc của trang web lưu trữ hình ảnh đó, ví dụ như
https://levanphu.info/robots.txtTrong tệp robots.txt sẽ có nội dung như sau:
User-agent: Googlebot-Image
Disallow: /images/lptech.jpgVào lần tiếp theo Google thu thập dữ liệu hình ảnh aothun.jpg, họ sẽ thấy quy tắc này và xoá hình ảnh đó khỏi kết quả tìm kiếm.
Cách 2: Xóa hình ảnh bằng header HTTP X-Robots-Tag noindex
Thêm X-Robots-Tag noindex vào header phản hồi HTTP của hình ảnh mà bạn muốn xoá. Sau đây là ví dụ về cách thêm quy tắc X-Robots-Tag noindex cho các tệp hình ảnh (.png, .jpeg, .jpg, .gif)
Riêng lẻ:
# the htaccess file must be placed in the directory of the matched file.
<Files "unicorn.pdf">
Header set X-Robots-Tag "noindex, nofollow"
</Files>Cho toàn bộ trang web:
<Files ~ "\.(png|jpe?g|gif)$">
Header set X-Robots-Tag "noindex"
</Files>Lý do của Làm mới tài liệu về việc xoá hình ảnh
Đây là quy trình làm mới tài liệu định kỳ của Google. Bản cập nhật này thuộc quá trình đó.
Ngày 8 tháng 2: Cập nhật phạm vi cung cấp Web Stories
Nội dung của Cập nhật phạm vi cung cấp Web Stories
Cập nhật phạm vi cung cấp tính năng của Web Stories. Hiện tại phạm vi cung cấp của Web Stories chỉ ở trong 3 nước là: Hoa Kỳ, Ấn Độ và Brazil
Về Web Stories: là phiên bản dựa trên nền tảng web của định dạng "Stories" thông dụng. Định dạng này kết hợp video, âm thanh, hình ảnh, ảnh động và văn bản để tạo ra trải nghiệm sinh động cho người xem.
Lý do của Cập nhật phạm vi cung cấp Web Stories
Để đảm bảo tài liệu của Google phù hợp với cách tính năng này xuất hiện trên Google Tìm kiếm, Web Stories không còn xuất hiện trong Google Hình ảnh nữa và chế độ xem lưới nay trở thành chế độ xem băng chuyền trong kết quả của Tìm kiếm.
Cập nhật nội dung mô tả mã sản phẩm Google-Extended
Nội dung của Cập nhật nội dung mô tả mã sản phẩm Google-Extended
Khi đổi tên Bard thành Ứng dụng Gemini, Google đã làm rõ việc Ứng dụng Gemini chịu ảnh hưởng của Google-Extended, và dựa trên ý kiến phản hồi của nhà xuất bản, Google đã làm rõ rằng Google-Extended không ảnh hưởng đến Google Tìm kiếm.
Về Google-Extended: là một mã token sản phẩm độc lập mà các web publisher có thể dùng để quản lý việc trang web của họ có giúp cải thiện các API tạo sinh của các ứng dụng Gemini và Vertex AI hay không.
Ngày 7 tháng 2: Cập nhật tần suất thu thập dữ liệu đối với mục tiêu của Quảng cáo tìm kiếm động
Nội dung: Cập nhật tần suất thu thập dữ liệu đối với các mục tiêu Quảng cáo tìm kiếm động trong hướng dẫn quản lý hạn mức thu thập dữ liệu.
Lý do: Để giảm áp lực trên các trang web, giờ đây, tần suất thu thập dữ liệu của Quảng cáo tìm kiếm động sẽ giảm đi, 21 ngày thay vì 14 ngày.
Lý thuyết chung về hoạt động thu thập dữ liệu
Thực tế, Google không thể khám phá và lập chỉ mục mọi URL đang tồn tại. Lượng thời gian và tài nguyên mà Google dành cho hoạt động thu thập dữ liệu có giới hạn trên một trang web thường được gọi là hạn mức thu thập dữ liệu của trang web đó.
Googlebot tính toán giới hạn công suất thu thập dữ liệu, mục đích để thu thập dữ liệu của tất cả nội dung quan trọng mà không làm quá tải máy chủ.
Googlebot sẽ tăng công suất thu thập dữ liệu nếu trang web phản hồi nhanh trong một khoảng thời gian. Nếu trang web chậm lại hoặc phản hồi bằng các lỗi máy chủ, mức giới hạn sẽ giảm xuống và Googlebot sẽ giảm tần suất thu thập dữ liệu.
Các phương pháp hay nhất
Phương pháp giúp bạn đạt được hiệu quả tối đa trong hoạt động thu thập dữ liệu:
- Quản lý các URL mà bạn đang có: Sử dụng các công cụ thích hợp để cho Google biết trang nào cần hay không cần thu thập dữ liệu.
- Hợp nhất nội dung trùng lặp
- Chặn thu thập dữ liệu URL bằng tệp robots.txt
- Hãy trả về mã trạng thái
404hoặc410đối với các trang đã xoá vĩnh viễn. - Loại bỏ lỗi
soft 404 - Thường xuyên cập nhật sơ đồ trang web
- Tránh các chuỗi chuyển hướng dài
- Cải thiện trang của bạn để tải dễ dàng hơn: vì Google có thể đọc được nhiều nội dung hơn trên trang web của bạn.
- Theo dõi hoạt động thu thập dữ liệu trên trang web: theo dõi và tìm cách tăng hiệu suất của quá trình thu thập dữ liệu.
Cải thiện hiệu quả thu thập dữ liệu đối với trang web
Tăng tốc độ tải trang
Sau đây là các lưu ý về cách tối ưu hoá các trang và tài nguyên cho hoạt động thu thập dữ liệu:
- Dùng tệp robots.txt để ngăn Googlebot tải các tài nguyên lớn nhưng không quan trọng.
- Đảm bảo rằng các trang tải nhanh.
- Chuỗi chuyển hướng dài gây ảnh hưởng tiêu cực đến hoạt động thu thập dữ liệu.
- Thời gian để phản hồi yêu cầu của máy chủ và thời gian cần thiết để kết xuất trang đều quan trọng, bao gồm cả thời gian tải và chạy các tài nguyên được nhúng như hình ảnh và tập lệnh.
Chỉ định nội dung thay đổi bằng mã trạng thái HTTP
Trạng thái HTTP được trình thu thập dữ liệu sử dụng:
If-Modified-Since có giá trị là ngày và giờ của lần gần đây nhất mà Google thu thập dữ liệu nội dung này.304 (Not Modified) trạng thái không có nội dung phản hồi.Ẩn những URL không muốn xuất hiện trong kết quả tìm kiếm
Dùng tệp robots.txt để chặn/ ẩn những URL nếu bạn không muốn Google thu thập dữ liệu và xuất hiện trên kết quả tìm kiếm thuộc các loại sau:
- URL điều hướng đa chiều và giá trị nhận dạng phiên.
- Nội dung trùng lặp
- Trang
soft 404 - Trang bị xâm nhập
- Không gian vô hạn và proxy
- Nội dung rác và chất lượng thấp
- Trang giỏ hàng, trang cuộn vô hạn và các trang thao tác (chẳng hạn như trang "đăng ký" hoặc "mua ngay").
- Nếu nhiều trang sử dụng cùng một tài nguyên (chẳng hạn như hình ảnh hoặc tệp JavaScript dùng chung).
Ngày 6 tháng 2: Xem xét lại tài liệu về JavaScript
Nội dung: Khắc phục các vấn đề về JavaScript liên quan đến Tìm kiếm và nội dung tải từng phần để xoá thông tin lỗi thời hoặc không cần thiết. Cập nhật tài liệu về cơ chế kết xuất động để làm rõ đó là một giải pháp không được dùng nữa.
Lý do: Cải thiện và làm rõ một số khía cạnh, một vài tính năng. Chẳng hạn như kết xuất động đã phát triển trong vài năm qua.
Để xác định JavaScript có làm trang của bạn (hoặc một số nội dung cụ thể trên các trang chạy bằng JavaScript) không thể xuất hiện trên Google Tìm kiếm hay không, hãy làm theo các bước sau đây:
Để kiểm tra cách thức Google thu thập dữ liệu và kết xuất URL: hãy sử dụng Công cụ kiểm tra URL trong Search Console. Nên thu thập và kiểm tra các lỗi JavaScript mà người dùng (bao gồm cả Googlebot) gặp phải trên trang web để xác định những vấn đề tiềm ẩn có thể ảnh hưởng đến cách hiển thị nội dung.
Tránh lỗi soft 404. Để ngăn Google lập chỉ mục các trang lỗi, bạn có thể sử dụng một hoặc cả hai chiến lược sau:
Chuyển hướng đến một URL mà máy chủ phản hồi bằng mã trạng thái 404.
Thêm hoặc thay đổi thẻ meta robots thành noindex
Googlebot sẽ từ chối các yêu cầu cấp quyền từ người dùng. Các tính năng đòi hỏi người dùng cho phép là không hợp lý đối với Googlebot cũng như đối với tất cả người dùng.
Đừng sử dụng URL phân mảnh để tải nhiều nội dung riêng biệt. Google đã ngừng sử dụng giao thức thu thập dữ liệu AJAX từ năm 2015, vì vậy bạn không nên sử dụng URL phân mảnh do chúng không phù hợp với Googlebot. Bạn nên dùng History API để tải những nội dung khác nhau dựa trên URL trong một SPA.
Đừng dựa vào khả năng lưu trữ cố định dữ liệu để phân phát nội dung. WRS tải từng URL bằng cách đi theo các lệnh chuyển hướng phía máy chủ và máy khách, giống như trình duyệt thông thường. Tuy nhiên, WRS không giữ lại các trạng thái sau mỗi lần tải trang:
Dữ liệu lưu tại Bộ nhớ cục bộ và Bộ nhớ phiên đều bị xóa sau mỗi lần tải trang.
Cookie HTTP cũng bị xóa sau mỗi lần tải trang.
Tạo và sử dụng vân tay số nội dung để Googlebot không gặp phải vấn đề khi lưu vào bộ nhớ đệm. Googlebot thường xuyên lưu nội dung vào bộ nhớ đệm để giảm số yêu cầu gửi đến các mạng cũng như giảm mức sử dụng tài nguyên. WRS có thể bỏ qua tiêu đề bộ nhớ đệm và sử dụng các tài nguyên JavaScript hoặc CSS đã cũ. Vân tay số nội dung có thể giúp bạn tránh vấn đề này bằng cách tạo vân tay số cho phần nội dung trong tên tệp, ví dụ như main.2bb85551.js.
Sử dụng chức năng phát hiện tính năng đối với mọi API quan trọng mà ứng dụng cần và cung cấp hành vi dự phòng hoặc polyfill khi thích hợp. Một số tác nhân người dùng có thể chưa phát hiện được một số tính năng trên web. Ngoài ra, vài tác nhân người dùng còn có thể cố ý vô hiệu hoá một số tính năng nhất định. Để khắc phục điều này, bạn có thể bỏ qua hiệu ứng ảnh hoặc sử dụng tính năng kết xuất phía máy chủ để kết xuất trước các hiệu ứng ảnh. Phương thức này sẽ giúp mọi người (kể cả Googlebot) truy cập được nội dung của bạn.
Đảm bảo nội dung có thể hoạt động trên kết nối HTTP. Googlebot sử dụng yêu cầu HTTP để truy xuất nội dung từ máy chủ của bạn và không hỗ trợ các loại kết nối khác, chẳng hạn như kết nối WebSockets hoặc WebRTC
Đảm bảo rằng các thành phần web hiển thị như mong đợi. Sử dụng Công cụ kiểm tra kết quả nhiều định dạng hoặc Công cụ kiểm tra URL để kiểm tra xem HTML được kết xuất đã có đủ toàn bộ nội dung mà bạn muốn hay chưa. WRS sẽ làm phẳng các DOM sáng và DOM tối. Nếu các thành phần web bạn sử dụng không dùng cơ chế <slot> cho nội dung trong DOM sáng, hãy tham khảo tài liệu của thành phần web để biết thêm thông tin hoặc sử dụng thành phần web khác.
Kiểm tra lại trang Web bằng Công cụ kiểm tra kết quả nhiều định dạng hoặc Công cụ kiểm tra URL trong Search Console.
Ngày 5 tháng 2: Một nghiên cứu điển hình mới
Nội dung: Thêm một nghiên cứu điển hình mới về Cách Wix tạo ra giá trị cho người dùng của họ bằng cách tích hợp các API của Google.
Lý do: Để giải thích cách một nền tảng CMS có thể trực tiếp tích hợp các API của Google vào giao diện người dùng của họ và tác động của việc đó đối với người dùng.
Tích hợp việc gửi sơ đồ trang web với Search Console
Nhờ sử dụng Site Verification API và Search Console API, Wix đã xây dựng được chức năng tự động xác minh quyền sở hữu trang web rồi gửi sơ đồ trang web tương ứng cho Search Console ngay trên trang tổng quan của Wix.
Công cụ kiểm tra trang web của Wix
Nhờ sử dụng URL Inspection API của Google, Wix đã giúp người dùng theo dõi các vấn đề về việc lập chỉ mục trang web của họ và kiểm tra các trang của họ ngay trên Trang tổng quan của Wix bằng cách gửi các trang đó đến API của Google.
Cơ chế tích hợp này sẽ kiểm tra trạng thái lập chỉ mục của một trang cụ thể (bao gồm cả mọi lỗi lập chỉ mục) và thực hiện hoạt động tổng hợp, ngoài nhiều chức năng khác. Nhờ vậy, người dùng Wix có thể nắm được thông tin tổng quan về tình trạng trang web của họ, cũng như nhận được thông tin mà họ cần để khắc phục mọi vấn đề cần thiết nhằm đảm bảo Google có thể lập chỉ mục nội dung của họ.
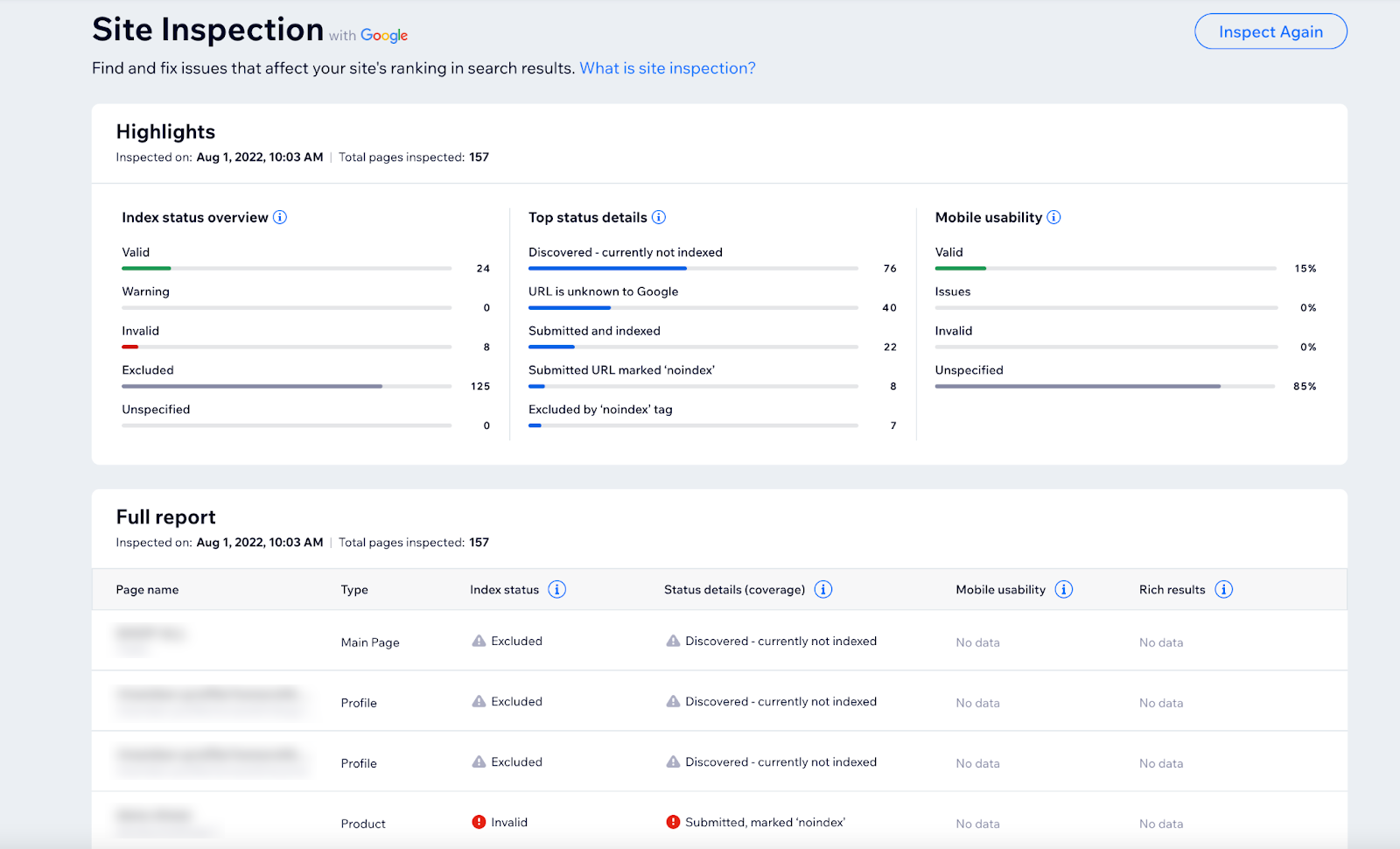
Báo cáo của Wix Analytics
Nhờ tận dụng chức năng báo cáo của Search Console API, Wix đã tạo ra 4 báo cáo mới để giúp người dùng nhận được thông tin chuyên sâu chi tiết về cách khách truy cập tương tác với trang web của họ bằng cách sử dụng các báo cáo SEO tích hợp.
Người dùng Wix có thể theo dõi số lượt nhấp, số lượt hiển thị, những thay đổi về lưu lượng truy cập và những cụm từ tìm kiếm chính ngay trên Trang tổng quan của Wix.
Đối với nhóm người dùng trang web trên Wix, Wix nhận thấy lưu lượng truy cập trung bình tăng 15% trong khoảng thời gian một năm kể từ khi họ kết nối với tài khoản Search Console thông qua cơ chế tích hợp API.
Ngoài ra, những trang web thương mại điện tử trên Wix sử dụng các tính năng mới trong một năm có GPV hằng tháng tăng 24%.
Việc tích hợp các API của Google vào Wix là một yếu tố đột phá đối với người dùng. Không chỉ tập trung vào số liệu phân tích; mà còn là đơn giản hoá toàn bộ quá trình tạo và tối ưu hoá trang web. Giúp họ theo dõi và khắc phục những vấn đề đang ảnh hưởng đến thứ hạng của họ trên công cụ tìm kiếm một cách hiệu quả hơn.
Ngày 2 tháng 2: Cải tiến Cẩm nang SEO
Vừa qua, Google đã cho ra mắt phiên bản mới được cải tiến với nội dung tin giản, rõ ràng hơn so với phiên bản 2008 trước đó.
Ở phiên bản này, Cẩm nang SEO sẽ tập trung hơn vào trải nghiệm của người đọc khi mới bắt đầu. Ngoài ra Google sẽ mang đến các chủ đề mà họ cho rằng người mới bắt đầu với SEO cần phải tập trung.
Tập trung cải thiện trải nghiệm người đọc
Thay vì dài dòng, lan man Google loại bỏ những biệt ngữ và từ đệm, tập trung đi vào vấn đề một cách nhanh chóng. Họ cũng viết lại phần giải thích các thuật ngữ theo cách dễ tiếp cận với người đọc. Đồng thời giải thích chi tiết lý do về các chủ đề và phương pháp SEO họ mang đến.
Một số thành phần bị loại bỏ trong bản cải tiến mới:
- Phần bảng thuật ngữ: Thay vào đó, Google sẽ giải thích từng thuật ngữ theo từng ngữ cảnh phù hợp để người đọc dễ nắm bắt.
- Phần dữ liệu có cấu trúc: nếu bạn đang dùng một hệ thống quản lý nội dung (CMS) như Wix hoặc Squarespace, thì bạn có thể dùng trình bổ trợ mà không cần lo về việc tìm hiểu cách thêm mã vào trang web.
- Mục mức độ thân thiện với thiết bị di động: vì hầu hết trang web hiện nay và nền tảng mới đều thân thiện với thiết bị di động.
- Phần phân tích hiệu suất trang web: Đây là một chủ đề nâng cao mà người mới bắt đầu chưa cần biết đến.
Bên cạnh việc loại bỏ các mục không cần thiết, Google đã tối ưu các yếu tố khác giúp nội dung trở nên cô đọng hơn để người đọc tập trung theo dõi vấn đề chính.
Các mục được tối ưu trong Cẩm nang SEO
Trong phiên bản mới, Google đã tối ưu và loại bỏ một số trong 8 mục nội dung dưới đây:
Xem thêm: Google cập nhật tài liệu cẩm nang SEO dành cho người mới 2024
Mục "Trang của bạn có xuất hiện trên Google không": Được đơn giản hóa và tập trung vào cách kiểm tra nhanh xem trang web có xuất hiện trên Google hay không.
Mục "Tôi có cần chuyên viên SEO không": Phần này được nén lại thành 2 câu và liên kết đến mục tài liệu hướng dẫn riêng.
Phần đường liên kết tiêu đề và đoạn trích: Được rút ngắn như mục trên và liên kết đến các tài liệu độc lập đầy đủ hơn.
Phần hình ảnh: Được loại bỏ, nếu bạn muốn khám phá, bạn có thể tìm hiểu thêm trong hướng dẫn các phương pháp hay về hình ảnh.

Phần "Chọn không xuất hiện trên Google Tìm kiếm": Được loại bỏ, Google cho rằng đây là một chủ đề không thực sự hữu ích khi người đọc tham khảo hướng dẫn này.
Phần đường liên kết: Được nén và làm nổi bật các khía cạnh hữu ích và lý do tại sao việc liên kết lại hữu ích đối với người dùng (và công cụ tìm kiếm).
Quảng bá trang web: Được nén và liên kết với Google cho Nhà sáng tạo
Phần cấu trúc trang web: Phần lớn được giữ nguyên nhưng loại bỏ một số thành phần:
Phần điều hướng: Google sẽ tập trung vào sự linh hoạt của các liên kết thay vì các URL quan trọng trên trang web.
Phần 404: Vì chúng ta thực sự không quan tâm đến các trang 404 và chủ sở hữu trang web chỉ nên làm bất cứ điều gì có ý nghĩa cho người dùng của họ.
Thiết lập rõ ràng cho breadcrumb: Đây là một chủ đề nâng cao hơn.
Google cải tiến Cẩm nang SEO với sự tập trung vào trải nghiệm đọc và cung cấp nội dung rõ ràng, cô đọng là một bước tiến quan trọng. Việc này giúp cho những người mới bắt đầu với SEO có thể tiếp cận thông tin một cách dễ dàng hơn và hiệu quả hơn.