
Xin chào tất cả các bạn! tôi là Phú Chuyên gia sản phẩm (Google Product Expert), và tôi vừa trở về từ một hành trình đầy cảm hứng tại Bangkok, Thái Lan, nơi tôi vinh dự được làm diễn giả tại sự kiện Google Search Central Live Deep Dive 2025. Ba ngày đắm mình trong thế giới của Google Search thực sự là một trải nghiệm không thể quên, nơi chúng ta cùng nhau "lặn sâu" vào những cơ chế cốt lõi nhất: thu thập dữ liệu, lập chỉ mục và phân phát kết quả tìm kiếm.
Sự kiện "Deep Dive" này không chỉ là nơi chia sẻ những lời khuyên SEO thông thường, mà còn là cơ hội hiếm có để chúng ta hiểu rõ hơn về cách Google Search thực sự vận hành từ bên trong.

Ảnh: Chụp tại sự kiện
Với vai trò là một diễn giả, tôi đã có dịp không chỉ chia sẻ những kiến thức của mình mà còn học hỏi được rất nhiều từ các đồng nghiệp và chuyên gia hàng đầu. Những hiểu biết sâu sắc về cách các hệ thống của Google hoạt động sẽ là kim chỉ nam quý giá, giúp chúng ta không chỉ theo kịp các xu hướng mà còn xây dựng các chiến lược tối ưu hóa hiệu quả và bền vững hơn cho năm 2025 và tương lai.
Mời các bạn xem qua bài viết recap sự kiện lần này cùng Phú nhé.
Ngày 1: Thu Thập Dữ Liệu (Crawling) và Tương Lai Của Tìm Kiếm Với AI
Ngày đầu tiên của Google Search Central Live Deep Dive 2025 tại Khách sạn Carlton Bangkok Sukhumvit đã mở màn với chủ đề trọng tâm là thu thập dữ liệu (crawling) và những thay đổi mang tính cách mạng mà AI đang mang lại cho thế giới tìm kiếm.
Mike Jittivanich, giám đốc tiếp thị khu vực Đông Nam Á và Nam Á Frontier, đã mở đầu bằng một bài phát biểu quan trọng, nhấn mạnh rằng chúng ta đang ở một thời điểm then chốt trong tìm kiếm.
Ông chỉ ra ba yếu tố chính đang định hình lại cục diện: sự đổi mới của AI đang cạnh tranh với những thay đổi lớn trong quá khứ như di động và mạng xã hội; các mô hình tiêu dùng của người dùng đang phát triển, với nhu cầu tìm kiếm thông tin nhanh hơn, đàm thoại hơn; và thói quen thay đổi của các thế hệ trẻ, những người tương tác với tìm kiếm khác biệt so với thế hệ trước.
Như Liz Reid, Phó Chủ tịch Tìm kiếm tại Google, đã nói, “Tìm kiếm không bao giờ là một vấn đề đã được giải quyết,” điều này càng khẳng định sự cần thiết của việc luôn linh hoạt và thích nghi.

Một trong những số liệu thống kê đáng chú ý nhất được đưa ra là sự phát triển nhanh chóng của Thế hệ Z (18-24 tuổi) trong việc sử dụng tìm kiếm. Việc sử dụng Google Lens của nhóm này đã tăng 65%so với cùng kỳ năm trước, với hơn 100 tỷ lượt tìm kiếm Lens tính đến năm 2025. Đáng chú ý, 1 trong 5 lượt tìm kiếm qua Lens hiện có ý định thương mại.

Người dùng trẻ tuổi cũng có xu hướng bắt đầu tìm kiếm theo những cách phi truyền thống, với khoảng 10% hành trình của họ bắt đầu bằng Circle to Search hoặc các trải nghiệm được hỗ trợ bởi AI khác, thay vì gõ vào hộp tìm kiếm truyền thống. Đối với các chuyên gia SEO, điều này có nghĩa là việc tối ưu hóa cho các truy vấn hình ảnh và giọng nói không còn là một lựa chọn mà đã trở thành một yêu cầu thiết yếu.

Các diễn giả cũng nhấn mạnh rằng các thuật toán xếp hạng học máy của Google học hỏi từ nội dung do con người tạo ra cho con người. Các mô hình này hiểu các mẫu ngôn ngữ tự nhiên và thưởng cho văn bản chân thực, giàu thông tin. Ngược lại, văn bản do AI tạo ra chiếm không gian riêng trong chỉ mục và hệ thống xếp hạng của Google không được đào tạo trên phần đó.
Gary Illyes giải thích rằng:
“Các thuật toán của chúng tôi đào tạo trên nội dung chất lượng cao nhất trong chỉ mục, rõ ràng là do con người tạo ra.”

Điều này khẳng định rằng việc tiếp tục tập trung vào nội dung được nghiên cứu kỹ lưỡng, hấp dẫn là chìa khóa. Các nguyên tắc cơ bản của SEO, như cấu trúc rõ ràng, từ khóa liên quan và liên kết nội bộ vững chắc, vẫn rất quan trọng. Không có danh sách kiểm tra riêng cho các tính năng AI; nếu bạn đang thực hiện SEO truyền thống tốt, bạn sẽ tự nhiên đủ điều kiện cho AI Overviews và các tính năng AI Mode.

Hai phiên thảo luận đã làm sáng tỏ cách AI đang tác động đến quá trình thu thập dữ liệu và lập chỉ mục:
Tác động thu thập dữ liệu của AI: Các trang web đang thấy tốc độ thu thập dữ liệu tăng lên khi Googlebot thích nghi với các tính năng mới được hỗ trợ bởi AI. Tuy nhiên, tốc độ thu thập dữ liệu cao hơn không tự động tăng thứ hạng.
Mã trạng thái và ngân sách thu thập dữ liệu: Chỉ các lỗi máy chủ (5XX) mới tiêu tốn ngân sách thu thập dữ liệu; mã 1XX và 4XX không ảnh hưởng đến nó, mặc dù 4XX có thể ảnh hưởng đến việc lập lịch và ưu tiên.

Cherry Prommawin đã giải thích rằng ngân sách thu thập dữ liệu là sản phẩm của giới hạn tốc độ thu thập dữ liệu (Googlebot có thể thu thập dữ liệu nhanh như thế nào) và nhu cầu thu thập dữ liệu (nó muốn thu thập dữ liệu bao nhiêu). Nếu trang web của bạn có liên kết bị hỏng hoặc phản hồi chậm, nó có thể làm chậm quá trình thu thập dữ liệu tổng thể.
Tìm kiếm của Google đang phát triển theo hai điểm tập trung chính: các loại truy vấn mà người dùng có thể đặt và phạm vi câu trả lời mà Google có thể cung cấp.
Các câu hỏi người dùng có thể hỏi: Các truy vấn đang trở nên dài hơn và đàm thoại hơn. Tìm kiếm từ năm từ trở lên đang tăng với tốc độ gấp 1,5 lần so với các truy vấn ngắn hơn. Ngoài văn bản, người dùng hiện thường xuyên chuyển sang giọng nói, hình ảnh và Circle to Search.
Kết quả Google có thể cung cấp: AI Overviews có thể tạo ra các bản tóm tắt cân bằng khi không có câu trả lời “đúng” duy nhất, trong khi AI Mode cung cấp trải nghiệm tạo sinh từ đầu đến cuối cho mua sắm, lập kế hoạch bữa ăn và các truy vấn đa phương thức. Google đang đưa các mô hình suy luận của DeepMind vào Tìm kiếm để cung cấp các kết quả phong phú hơn, sắc thái hơn này, pha trộn văn bản, hình ảnh và hướng dẫn định hướng hành động trong một giao diện duy nhất.
Gary Illyes và Amir Taboul đã thảo luận về lập trường của Google đối với robots.txt và tiêu chuẩn LLMs.txt được đề xuất của nhóm làm việc IETF. Giống như các từ khóa meta cũ, LLMs.txt không phải là một sáng kiến của Google và không được coi là có lợi, hoặc là thứ mà họ đang tìm cách áp dụng. Quan điểm của Google là robots.txt vẫn là tiêu chuẩn tự nguyện chính để kiểm soát trình thu thập dữ liệu. Nếu bạn chọn chặn các bot cụ thể của AI, bạn có thể làm như vậy trong robots.txt, nhưng hãy biết rằng không phải tất cả các trình thu thập dữ liệu AI sẽ tuân theo nó.
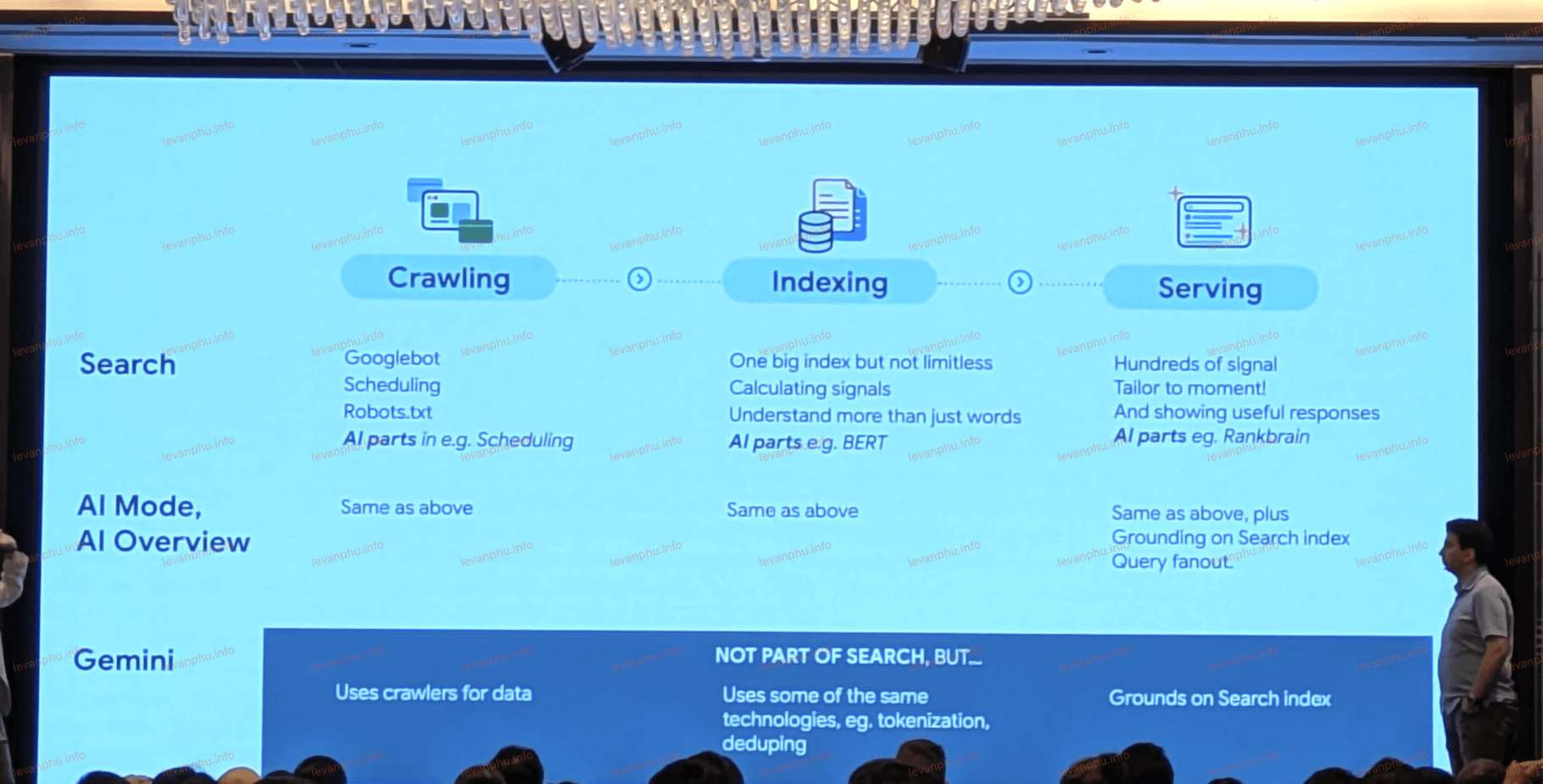
AI Mode và AI Overviews dựa trên cùng một cơ sở hạ tầng thu thập dữ liệu, lập chỉ mục và phân phát như Tìm kiếm truyền thống. Googlebot xử lý cả kết quả liên kết xanh và các tính năng AI, trong khi các trình thu thập dữ liệu khác trong cùng hệ thống cung cấp Gemini và các mô hình ngôn ngữ lớn (LLM).
Mỗi trang vẫn trải qua quá trình phân tích cú pháp HTML, hiển thị, loại bỏ trùng lặp và các mô hình thống kê, chẳng hạn như BERT, để hiểu và phát hiện thư rác khi đến lúc phân phát kết quả.

Các quy trình diễn giải truy vấn và tín hiệu xếp hạng tương tự, chẳng hạn như RankBrain, MUM và các mô hình ML khác, sắp xếp thông tin cho cả liên kết xanh cổ điển và câu trả lời được hỗ trợ bởi AI. AI Mode và AI Overviews chỉ đơn giản là các tính năng giao diện người dùng mới được xây dựng trên các nền tảng Tìm kiếm quen thuộc mà các SEO đã tối ưu hóa từ trước đến nay.
Cuối cùng, Daniel Waisberg đã dẫn dắt một phiên về việc sử dụng hiệu quả Search Console trong kỷ nguyên mới này. Daniel mô tả Search Console là cầu nối giữa cơ sở hạ tầng của Google (thu thập dữ liệu, lập chỉ mục, phân phát) và trang web của bạn. Các điểm chính từ các phiên này bao gồm:
Độ trễ dữ liệu: Dữ liệu cuối cùng trong Search Console thường có độ trễ hai ngày, dựa trên múi giờ Thái Bình Dương. Dữ liệu một phần và gần cuối cùng nằm phía sau hậu trường và có thể khác nhau tới 1%.
Vòng đời tính năng: Các cải tiến mới tiến triển từ nhu cầu người dùng đến dữ liệu có sẵn, sau đó thông qua thiết kế và phát triển, đến thử nghiệm và ra mắt.
Tính năng đề xuất: Công cụ này nhằm vào những người dùng không phải là chuyên gia dữ liệu, gợi ý các cải tiến có thể hành động mà không làm họ choáng ngợp.
Bằng cách hiểu cách Search Console trình bày dữ liệu, bạn có thể chẩn đoán các vấn đề thu thập dữ liệu, theo dõi hiệu suất và xác định các cơ hội cho các tính năng dựa trên AI.
Ngày 2: Khám Phá Chuyên Sâu Về Lập Chỉ Mục (Indexing) – Từ HTML đến API Google Trends
Ngày thứ hai của Google Search Central Live APAC 2025 đã đưa chúng ta vào thế giới phức tạp của việc lập chỉ mục, một bước quan trọng sau quá trình thu thập dữ liệu.

Quá Trình Phân Tích Cú Pháp HTML và Các Giai Đoạn Lập Chỉ Mục
Cherry Prommawin đã trình bày một cách chi tiết cách Google xử lý HTML và các giai đoạn chính của việc lập chỉ mục. Quá trình này bao gồm các bước tuần tự: phân tích cú pháp HTML, kết xuất và thực thi JavaScript, loại bỏ trùng lặp, trích xuất tính năng và trích xuất tín hiệu.

Cherry cũng nhấn mạnh rằng Google chuẩn hóa HTML thô thành DOM (Mô hình Đối tượng Tài liệu), sau đó tìm các phần tử tiêu đề và điều hướng, và xác định phần nào chứa nội dung chính của trang. Trong quá trình này, Google cũng trích xuất các phần tử quan trọng như rel=canonical, hreflang, liên kết và neo, và thẻ meta-robots. Một điểm đáng chú ý là Google không có sự ưu tiên giữa các trang web đáp ứng (responsive) và các trang web động/thích ứng (dynamic/adaptive) khi lập chỉ mục.
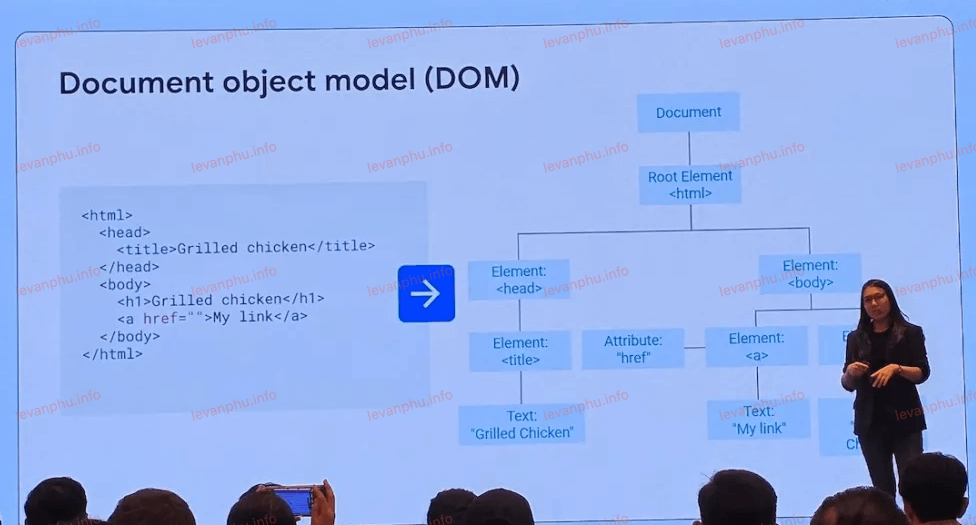
Việc Google phải trải qua nhiều bước phức tạp như kết xuất JavaScript cho thấy rằng công cụ tìm kiếm này không chỉ đơn thuần đọc mã nguồn mà còn "trải nghiệm" trang web gần giống như một trình duyệt thực. Điều này có nghĩa là các nhà phát triển web và SEO cần đảm bảo rằng nội dung cốt lõi của họ dễ dàng được Google nhận diện và truy cập sau khi kết xuất.
Việc xác định nội dung chính là một bước thiết yếu để Google hiểu trọng tâm của trang. Gary Illyes cũng đã chỉ ra rằng nội dung chính, được định nghĩa bởi Nguyên tắc đánh giá chất lượng của Google, là yếu tố quan trọng nhất trong việc thu thập dữ liệu và lập chỉ mục.

Ổng còn lưu ý rằng việc chuyển một chủ đề vào khu vực nội dung chính có thể trực tiếp làm tăng thứ hạng. Điều này liên kết chặt chẽ với nguyên tắc "nội dung ưu tiên con người" được nhắc đến trong phiên thảo luận về chất lượng ở Ngày 3, cho thấy sự nhất quán trong triết lý của Google.
Vai Trò Của Robots.txt và Thẻ Meta-robots
Gary Illyes đã làm rõ vai trò riêng biệt nhưng bổ trợ của robots.txt và thẻ meta-robots. Ông giải thích rằng robots.txt kiểm soát những gì trình thu thập dữ liệu của Google có thể tìm nạp (crawl), trong khi thẻ meta-robots kiểm soát cách dữ liệu đã tìm nạp được sử dụng ở các giai đoạn sau, tức là trong quá trình lập chỉ mục và phân phát kết quả.

Ông cũng nêu bật một số chỉ thị ít được biết đến hơn nhưng vẫn hoạt động hiệu quả. Ví dụ, chỉ thị none tương đương với việc kết hợp noindex,nofollow thành một quy tắc duy nhất.
Notranslate sẽ ngăn Chrome đề xuất dịch trang. Noimageindex không chỉ áp dụng cho hình ảnh mà còn cả cho các tài sản video. Và chỉ thị unavailable after, mặc dù được giới thiệu bởi các kỹ sư đã chuyển đi, vẫn hoạt động bình thường.
Sự phân biệt rõ ràng giữa robots.txt và meta-robots tạo ra một hệ thống kiểm soát hai lớp cho các nhà quản trị web. Lớp đầu tiên là về việc cấp quyền cho Googlebot truy cập và tải xuống nội dung của trang. Lớp thứ hai là về việc Google nên làm gì với nội dung đó sau khi nó đã được tải xuống.
Một trang có thể được thu thập dữ liệu (không bị chặn bởi robots.txt) nhưng lại không được lập chỉ mục (do noindex trong thẻ meta-robots). Điều này có nghĩa là việc "cho phép crawl" không đồng nghĩa với việc "cho phép index". Sự hiểu lầm này có thể dẫn đến các vấn đề về khả năng hiển thị.
Do đó, các chuyên gia SEO cần hiểu rõ sự khác biệt này để tránh các lỗi phổ biến, chẳng hạn như chặn một trang bằng robots.txt nhưng lại mong muốn nó được lập chỉ mục (điều không thể xảy ra vì Google không thể đọc thẻ meta-robots nếu nó không thể thu thập dữ liệu trang). Ngược lại, việc sử dụng noindex trên một trang đã được thu thập dữ liệu là cách chính xác để loại bỏ nó khỏi chỉ mục mà không cần chặn crawl. Các chỉ thị ít được biết đến cung cấp các tùy chọn kiểm soát tinh vi hơn cho các trường hợp sử dụng cụ thể, giúp quản lý tốt hơn cách nội dung được hiển thị trong kết quả tìm kiếm.
Chiến Lược Loại Bỏ Trùng Lặp và Bản Địa Hóa Của Google
Cherry Prommawin đã giải thích việc loại bỏ trùng lặp trong ba lĩnh vực trọng tâm. Thứ nhất là phân cụm, trong đó Google sử dụng chuyển hướng, sự tương đồng nội dung và rel=canonical để nhóm các trang trùng lặp. Thứ hai là kiểm tra nội dung, thông qua tổng kiểm tra bỏ qua các phần tử lặp lại và phát hiện nhiều trang lỗi mềm. Cuối cùng là bản địa hóa, nơi các trang chỉ khác nhau theo ngôn ngữ (ví dụ thông qua chuyển hướng địa lý), hreflang sẽ kết nối chúng mà không bị phạt.
Cherry cũng đối chiếu giữa chuyển hướng vĩnh viễn (301) và tạm thời (302), lưu ý rằng chỉ chuyển hướng vĩnh viễn mới ảnh hưởng đến URL được chọn làm canonical của cụm. Một điểm quan trọng khác là Google ưu tiên rủi ro chiếm quyền điều khiển trước, trải nghiệm người dùng thứ hai và tín hiệu của chủ sở hữu trang web (như rel=canonical của bạn) thứ ba khi chọn URL đại diện.

Điều này cho thấy Google sử dụng nhiều tín hiệu để xác định trang canonical, không chỉ dựa vào một yếu tố duy nhất. Thứ tự ưu tiên của Google khi chọn canonical (rủi ro chiếm quyền điều khiển > trải nghiệm người dùng > tín hiệu của nhà quản trị web) cho thấy Google đặt an toàn và trải nghiệm người dùng lên hàng đầu, ngay cả khi điều đó có nghĩa là bỏ qua tín hiệu rel=canonical của nhà quản trị web trong một số trường hợp. Điều này có ý nghĩa quan trọng đối với SEO quốc tế.
Thay vì lo lắng về nội dung trùng lặp giữa các phiên bản ngôn ngữ/khu vực, các chuyên gia SEO nên tập trung vào việc triển khai hreflang chính xác. Cherry nhấn mạnh rằng không cần phải ẩn nội dung trùng lặp trên hai trang web dành riêng cho quốc gia; hreflang sẽ xử lý các lựa chọn thay thế đó. Các tín hiệu nhắm mục tiêu địa lý chính mà Google sử dụng là: tên miền cấp cao nhất theo mã quốc gia (ccTLD), chú thích

Hreflang, vị trí máy chủ, và các tín hiệu địa phương bổ sung như ngôn ngữ và tiền tệ trên trang, các liên kết từ các trang web khu vực khác và các tín hiệu từ Hồ sơ doanh nghiệp địa phương của bạn. Việc kết hợp
hreflang với ccTLD và các tín hiệu địa phương khác sẽ xây dựng một cấu trúc mạnh mẽ, giúp Google hiểu rõ đối tượng mục tiêu của từng phiên bản trang, tối ưu hóa việc phân phối nội dung phù hợp cho người dùng trên toàn cầu.
PageRank Nội Bộ và SpamBrain
Gary Illyes đã xác nhận rằng Google vẫn sử dụng PageRank nội bộ sau giai đoạn trích xuất tính năng. PageRank là một trong những thuật toán nền tảng của Google, tập trung vào cấu trúc liên kết. Việc nó vẫn được sử dụng cho thấy tầm quan trọng lâu dài của các tín hiệu liên kết nội bộ trong việc hiểu cấu trúc và quyền hạn của trang web.
Gary cũng tiết lộ rằng các hệ thống của Google xác định khoảng 40 tỷ trang spam mỗi ngày, được hỗ trợ bởi "SpamBrain" dựa trên mô hình ngôn ngữ lớn (LLM) của họ. SpamBrain dựa trên LLM đại diện cho sự tiến bộ vượt bậc trong việc sử dụng AI để nhận diện các mẫu spam phức tạp và quy mô lớn.

Đây là một ví dụ rõ ràng về việc Google kết hợp các nguyên tắc cốt lõi đã được chứng minh (như PageRank) với các công nghệ AI tiên tiến (như LLM) để duy trì chất lượng và sự liên quan của kết quả tìm kiếm. Nó không phải là một sự thay thế hoàn toàn mà là một sự bổ sung và nâng cấp.
Đối với SEO, điều này có nghĩa là việc tối ưu hóa cấu trúc liên kết nội bộ vẫn là một thực hành quan trọng. Đồng thời, việc tránh mọi hình thức spam (đặc biệt là các chiến thuật thao túng nội dung hoặc liên kết) trở nên cấp thiết hơn bao giờ hết, vì các hệ thống AI của Google ngày càng tinh vi trong việc phát hiện chúng.
Hình Ảnh AI và Thông Báo Lớn về API Google Trends (Alpha)
Trong phiên thảo luận, Ian Huang đã trình bày rằng Google không quan tâm liệu hình ảnh của bạn được tạo bởi AI hay con người, miễn là chúng truyền tải thông tin một cách chính xác và hiệu quả. Quan điểm này cho thấy Google tập trung vào chất lượng và mục đích của nội dung, không phải cách thức tạo ra nó. Điều này phù hợp với nguyên tắc "nội dung ưu tiên con người" mà chúng ta sẽ tìm hiểu sâu hơn ở Ngày 3.
Các nhà sáng tạo nội dung có thể tự tin sử dụng công cụ AI để tạo hình ảnh, miễn là chúng có chất lượng cao và phù hợp với nội dung.
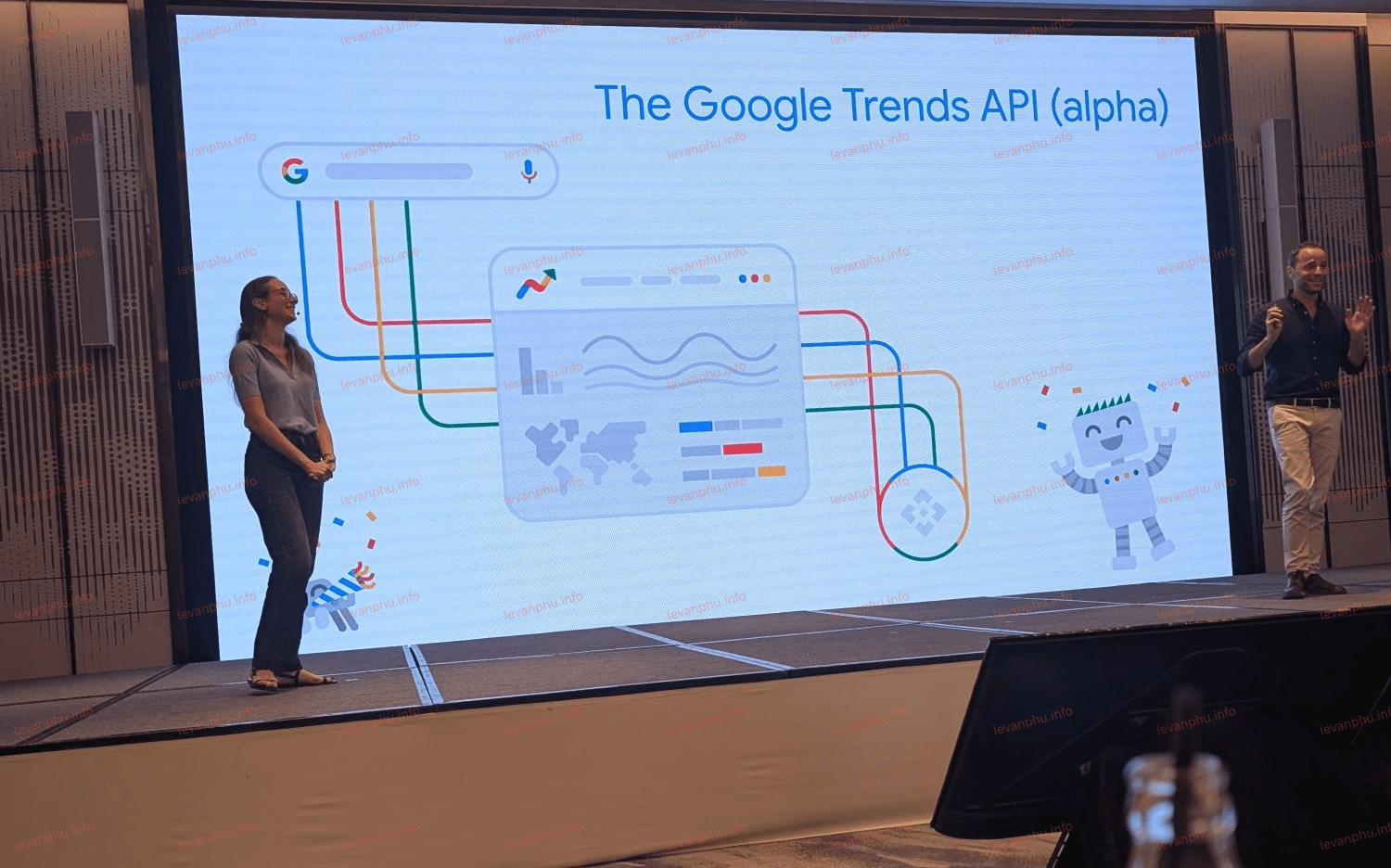
Cuối cùng, Daniel Waisberg và Hadas Jacobi đã công bố API Google Trends (Alpha) mới. Đây là một thông báo lớn cho cộng đồng SEO và marketing. Các tính năng chính của API mới sẽ bao gồm: dữ liệu mức độ quan tâm tìm kiếm được điều chỉnh nhất quán, không hiệu chỉnh lại khi bạn thay đổi truy vấn; cửa sổ cuộn năm năm, được cập nhật tối đa 48 giờ trước, để so sánh theo mùa và lịch sử; tổng hợp thời gian linh hoạt (hàng tuần, hàng tháng, hàng năm); và phân tích theo khu vực và tiểu khu vực.

API Trends mới này trực tiếp hỗ trợ việc tạo nội dung "ưu tiên con người" bằng cách cung cấp dữ liệu sâu sắc về những gì người dùng đang tìm kiếm và quan tâm. Đây là một công cụ thay đổi cuộc chơi cho việc nghiên cứu từ khóa, lập kế hoạch nội dung và theo dõi xu hướng thị trường, cho phép phân tích dữ liệu tìm kiếm sâu hơn và đưa ra quyết định dựa trên dữ liệu tốt hơn.
Ngày 3: Đi Sâu Vào Cách Google Phân Phát và Đánh Giá Chất Lượng (Serving & Quality) – Từ Truy Vấn Đến Trải Nghiệm Người Dùng
Ngày cuối cùng của sự kiện đã đi sâu vào cách Google thực sự trả về kết quả tìm kiếm, tập trung vào việc hiểu truy vấn và đánh giá chất lượng.
Cơ Sở Hạ Tầng Phân Phát và Cách Google Hiểu Truy Vấn Người Dùng
Cơ sở hạ tầng phân phát của Google bao gồm nhiều bước phức tạp: hiểu truy vấn, truy xuất kết quả, lựa chọn chỉ mục, xếp hạng và áp dụng tính năng (bao gồm kết quả phong phú), trước khi hiển thị chúng cho người dùng.
Cherry Prommawin đã giải thích chi tiết cách Google diễn giải các truy vấn của người dùng. Không phải tất cả các truy vấn đều đơn giản. Trong các ngôn ngữ như tiếng Trung hoặc tiếng Nhật, không có khoảng trắng giữa các từ, vì vậy Google phải học cách các từ bắt đầu và kết thúc bằng cách xem xét các truy vấn và tài liệu trong quá khứ. Điều này được gọi là phân đoạn, và không phải tất cả các ngôn ngữ đều yêu cầu điều này.

Sau đó, Google loại bỏ các từ dừng trừ khi chúng là một phần của cụm từ hoặc thực thể có ý nghĩa, như “Chúa tể của những chiếc nhẫn.” Cuối cùng, nó mở rộng truy vấn để bao gồm các từ đồng nghĩa trên tất cả các ngôn ngữ để khớp tốt hơn với những gì người dùng đang thực sự tìm kiếm.
Bối cảnh đóng một vai trò quan trọng trong cách Google hiểu và phản hồi các truy vấn. Một khía cạnh quan trọng của điều này là việc sử dụng các từ đồng nghĩa theo ngữ cảnh. Đây không giống như các từ đồng nghĩa điển hình mà bạn tìm thấy trong từ điển tiếng Anh. Thay vào đó, chúng được tạo ra để giúp trả về kết quả tìm kiếm tốt hơn, dựa trên cách các từ được sử dụng trong các tìm kiếm và nội dung trong thế giới thực.

Google có thể biết rằng những người tìm kiếm “thuê xe hơi” thường nhấp vào các trang có nội dung “xe cho thuê”, vì vậy nó coi hai thuật ngữ này là tương tự trong ngữ cảnh phù hợp. Đây là điều mà Google gọi là “anh chị em”. Những mối quan hệ này hầu hết vô hình đối với người dùng, nhưng chúng giúp kết nối các truy vấn với thông tin phù hợp nhất, ngay cả khi các từ chính xác không khớp.
Điều này cho thấy Google không chỉ đơn thuần khớp các từ khóa. Nó thực hiện phân tích ngôn ngữ sâu sắc để hiểu cấu trúc câu, ý nghĩa của các cụm từ, và mối quan hệ ngữ nghĩa giữa các từ trong các ngữ cảnh khác nhau.
Khái niệm "anh chị em" đặc biệt quan trọng vì nó thể hiện khả năng của Google trong việc nhận diện các cụm từ có ý nghĩa tương tự dựa trên hành vi người dùng và dữ liệu thực tế, không chỉ dựa vào từ điển. Sự hiểu biết sâu sắc về truy vấn này là nền tảng cho việc phân phát kết quả tìm kiếm có liên quan cao.

Nếu Google có thể hiểu được ý định thực sự của người dùng, nó có thể cung cấp các kết quả chính xác hơn, ngay cả khi người dùng sử dụng các từ khóa không hoàn hảo. Đối với SEO, điều này có nghĩa là việc tối ưu hóa chỉ dựa trên từ khóa đơn lẻ là không đủ.
Chúng ta cần tập trung vào việc tạo nội dung bao quát các chủ đề, trả lời các câu hỏi tiềm ẩn và sử dụng ngôn ngữ tự nhiên, đa dạng, bao gồm các từ đồng nghĩa và các cụm từ liên quan mà người dùng có thể sử dụng. Mục tiêu là phục vụ ý định tìm kiếm, không chỉ các từ khóa cụ thể.
Định Nghĩa Chất Lượng Của Google và 4 vấn đề cần lưu ý
Alfin Hotario Ho đã giải thích rõ ràng cách Google đánh giá chất lượng trong kết quả tìm kiếm. Chất lượng chỉ là một trong nhiều tín hiệu mà Google sử dụng khi xếp hạng các trang, nhưng nó là một tín hiệu quan trọng. Trong những năm qua, Google đã cố gắng định nghĩa “chất lượng” có nghĩa là gì, và nó luôn quay trở lại năm điểm chính: tập trung vào nội dung ưu tiên con người, chuyên môn, nội dung và chất lượng, trình bày và sản xuất, và tránh tạo nội dung ưu tiên công cụ tìm kiếm.
Ông Ho nhấn mạnh Hướng dẫn đánh giá chất lượng (Quality Rater Guidelines) là một nguồn tài nguyên hữu ích. Những hướng dẫn này không ảnh hưởng trực tiếp đến thứ hạng, nhưng chúng giúp giải thích cách Google đo lường xem hệ thống của mình có hoạt động tốt hay không. Khi các hướng dẫn thay đổi, chúng phản ánh các bản cập nhật trong suy nghĩ của Google về những gì tạo nên nội dung tốt.
Việc Google liên tục quay trở lại 5 điểm và 4 trụ cột cho thấy đây là những nguyên tắc nền tảng và ổn định trong triết lý xếp hạng của họ. Mặc dù QRG không phải là thuật toán, nhưng nó là kim chỉ nam cho các kỹ sư Google trong việc xây dựng và tinh chỉnh các thuật toán.
Có 4 vấn đề chính về chất lượng:
- Nỗ lực: Nội dung phải được tạo ra cho con người, không phải công cụ tìm kiếm. Nó phải thể hiện rõ ràng thời gian, kỹ năng và kiến thức trực tiếp.
- Tính độc đáo: Nội dung phải cung cấp một cái gì đó mới – nghiên cứu gốc, phân tích mới hoặc báo cáo vượt ra ngoài những gì đã có.
- Chuyên môn: Nội dung phải được viết hoặc sản xuất tốt, không có lỗi rõ ràng và thể hiện mức độ thủ công cao. Bạn cũng không cần phải là một chuyên gia về một lĩnh vực nào đó, miễn là bạn có thể chứng minh kinh nghiệm trực tiếp có thể kiểm chứng được.
- Độ chính xác: Nội dung phải đúng sự thật, được hỗ trợ bởi bằng chứng và nhất quán với ý kiến chuyên gia hoặc sự đồng thuận của công chúng nếu có thể.
Điều này ngụ ý rằng "chất lượng" không chỉ là một tín hiệu mà Google tìm kiếm, mà là một mục tiêu tổng thể mà toàn bộ hệ thống tìm kiếm hướng tới. Các bản cập nhật thuật toán thường phản ánh nỗ lực của Google để tốt hơn trong việc nhận diện và thưởng cho nội dung đáp ứng các tiêu chí chất lượng này.
Đối với SEO, việc tạo nội dung chất lượng cao không phải là một tùy chọn mà là một yêu cầu cơ bản. Các nhà xuất bản nên coi QRG là một tài liệu hướng dẫn để hiểu "tư duy" của Google về nội dung tốt. Tập trung vào việc thể hiện nỗ lực, tính độc đáo, kỹ năng và độ chính xác sẽ giúp nội dung của bạn phù hợp với những gì Google muốn hiển thị cho người dùng.
E-E-A-T và Sự Tin Cậy
Từ E-E-A-T (Kinh nghiệm, Chuyên môn, Quyền hạn và Độ tin cậy), rõ ràng là sự tin cậy (Trust) quan trọng nhất. Ngay cả khi một chủ đề không liên quan đến sức khỏe, tiền bạc hoặc sự an toàn (Your Money or Your Life – YMYL), Google vẫn ưu tiên nội dung đáng tin cậy. Nếu một trang không đồng ý mạnh mẽ với ý kiến chuyên gia chung, nó có thể bị coi là kém tin cậy hơn.

Điều này mở rộng phạm vi ứng dụng của Trust vượt ra ngoài các chủ đề nhạy cảm về YMYL. Nó cho thấy rằng Google muốn người dùng tin tưởng vào thông tin mà họ tìm thấy, bất kể chủ đề là gì. Nếu Trust là yếu tố quan trọng nhất, nó ngụ ý rằng các yếu tố khác của E-E-A-T (Experience, Expertise, Authoritativeness) đều phục vụ để xây dựng Trust. Một trang có kinh nghiệm, chuyên môn và quyền hạn cao sẽ có khả năng được coi là đáng tin cậy hơn.
Do đó, các nhà xuất bản nội dung cần tập trung vào việc xây dựng và thể hiện sự đáng tin cậy của mình thông qua tính chính xác, minh bạch, và sự nhất quán với các nguồn thông tin uy tín. Điều này có thể bao gồm việc trích dẫn nguồn rõ ràng, cung cấp thông tin về tác giả, và duy trì một hồ sơ trực tuyến đáng tin cậy.
Các Bản Cập Nhật Chất Lượng Của Google và Cách Khôi Phục
Google cập nhật hệ thống tìm kiếm của mình vì 3 lý do chính: để hỗ trợ các định dạng nội dung mới, để nâng cao chất lượng nội dung hoặc để chống lại thư rác.
Hỗ trợ các định dạng nội dung mới: Khi các loại nội dung mới trở nên phổ biến hơn, chẳng hạn như video ngắn hoặc hình ảnh tương tác, người dùng bắt đầu mong đợi tìm thấy chúng trong kết quả tìm kiếm. Nếu đủ người thể hiện sự quan tâm, Google có thể ra mắt các tính năng mới để đáp ứng nhu cầu đó.

Cải thiện phạm vi và mức độ liên quan của nội dung (Core Updates): Internet không ngừng phát triển, và nhiều chủ đề trở nên bão hòa. Điều đó khiến việc tìm kiếm nội dung tốt nhất trở nên khó khăn hơn. Để cải thiện điều này, Google triển khai các bản cập nhật cốt lõi. Những bản cập nhật này không nhắm mục tiêu vào các trang web hoặc trang cụ thể. Thay vào đó, chúng cải thiện cách Google xếp hạng nội dung trên web với mục tiêu bao quát là hiển thị kết quả chất lượng cao hơn.
Chống lại nội dung chất lượng thấp và thư rác (Spam Updates): Một số người cố gắng lách luật bằng nội dung ít nỗ lực. Google không hoàn hảo, và những kẻ gửi thư rác tìm kiếm những lỗ hổng để khai thác. Để đáp lại, Google ra mắt các bản cập nhật được nhắm mục tiêu điều chỉnh cách hệ thống của nó phát hiện thư rác hoặc tín hiệu chất lượng thấp.
Việc phân loại các bản cập nhật theo mục đích (đổi mới, cải thiện, bảo vệ) giúp các chuyên gia SEO hiểu rõ hơn về động lực đằng sau những thay đổi của Google. Quan trọng hơn, lời khuyên về cách khôi phục cho thấy một sự khác biệt cơ bản giữa các bản cập nhật cốt lõi và các bản cập nhật thư rác.
Khôi phục từ các bản cập nhật cốt lõi: Bạn về mặt kỹ thuật không bị phạt, vì vậy về mặt kỹ thuật không có sự khôi phục nào như với các bản cập nhật thư rác. Google khuyên bạn nên: “Tiếp tục làm tốt công việc, xem xét những gì đối thủ cạnh tranh của bạn đang làm tốt hơn và học hỏi từ các trang web đang làm tốt hơn bạn.”.
Nếu một trang web bị ảnh hưởng bởi một bản cập nhật cốt lõi, đó không phải là do nó đã làm gì "sai" mà là do Google đã tìm ra cách tốt hơn để đánh giá chất lượng tổng thể và các trang khác có thể đang làm tốt hơn.
Khôi phục từ các bản cập nhật thư rác: Cần xóa loại thư rác mà Google đã đề cập trong các thông báo trên blog của mình. Ngược lại, một bản cập nhật thư rác là một sự trừng phạt trực tiếp cho việc vi phạm nguyên tắc.
Các nhà quản trị web cần phân biệt rõ ràng loại bản cập nhật đã ảnh hưởng đến trang của mình. Đối với các bản cập nhật cốt lõi, trọng tâm nên là cải thiện chất lượng nội dung tổng thể, trải nghiệm người dùng, và phân tích đối thủ cạnh tranh để hiểu những gì Google hiện đang ưu tiên. Đối với các bản cập nhật thư rác, cần có hành động khắc phục cụ thể và nhanh chóng để loại bỏ các yếu tố spam đã được xác định.
Những Lầm Tưởng Về Dữ Liệu Có Cấu Trúc
Google đã giải quyết một số lầm tưởng phổ biến xung quanh dữ liệu có cấu trúc, đặc biệt là mối liên hệ của nó với việc phân phát và xếp hạng.
Không phải là yếu tố xếp hạng trực tiếp: Thêm dữ liệu có cấu trúc vào trang web của bạn sẽ không trực tiếp cải thiện thứ hạng của bạn. Nhưng, nó có thể làm cho danh sách của bạn hấp dẫn hơn trong kết quả tìm kiếm, điều này có thể dẫn đến nhiều nhấp chuột hơn. Sự tương tác tăng thêm đó có thể giúp trang web của bạn theo thời gian.
Không chắc chắn: Khi bạn đã thêm dữ liệu có cấu trúc không có nghĩa là Google sẽ hiển thị kết quả phong phú. Các thuật toán quyết định khi nào và ở đâu việc hiển thị chúng có ý nghĩa.
Google có thể tự thêm kết quả phong phú: Ngay cả khi không có dữ liệu có cấu trúc, Google vẫn có thể hiển thị kết quả nâng cao, chẳng hạn như tên trang web hoặc đường dẫn của bạn, nếu nó có thể suy ra thông tin đó từ nội dung trang của bạn.
Cần bảo trì liên tục: Dữ liệu có cấu trúc không phải là một nhiệm vụ một lần. Bạn nên kiểm tra thường xuyên để đảm bảo nó vẫn chính xác và không có lỗi. Việc cập nhật nó giúp bạn đủ điều kiện nhận các tính năng tìm kiếm nâng cao.
Đây là một lời nhắc nhở quan trọng rằng dữ liệu có cấu trúc chủ yếu là một công cụ để làm phong phú kết quả tìm kiếm và cải thiện khả năng hiểu của Google về nội dung, chứ không phải là một "công tắc" để tăng thứ hạng. Mặc dù không trực tiếp là yếu tố xếp hạng, việc tăng CTR (do kết quả phong phú) có thể dẫn đến nhiều lưu lượng truy cập hơn, và nếu người dùng có trải nghiệm tốt trên trang, điều này có thể gián tiếp gửi tín hiệu tích cực đến Google theo thời gian.
Các chuyên gia SEO nên coi dữ liệu có cấu trúc là một phần của chiến lược tối ưu hóa trải nghiệm người dùng và khả năng hiển thị, chứ không phải là một cách để "lừa" thuật toán. Việc triển khai chính xác và bảo trì thường xuyên là chìa khóa để tận dụng tối đa lợi ích của nó, đảm bảo rằng Google có thể hiểu nội dung của bạn một cách tốt nhất để hiển thị các tính năng tìm kiếm nâng cao.
Những Thông tin Quan Trọng Từ Google Search Central Live Deep Dive 2025
Ba ngày tại Google Search Central Live Deep Dive 2025 đã mang lại vô số thông tin chi tiết về cách Google thu thập dữ liệu, lập chỉ mục và phân phát kết quả tìm kiếm. Chúng ta đã có cái nhìn sâu sắc hơn về quy trình lập chỉ mục phức tạp, sự khác biệt quan trọng giữa robots.txt và meta-robots, đến các chiến lược loại bỏ trùng lặp và bản địa hóa tinh vi của Google.

Chúng tôi cũng đã khám phá cách Google hiểu truy vấn người dùng thông qua phân tích ngữ cảnh và từ đồng nghĩa "anh chị em", cũng như định nghĩa chất lượng cốt lõi của họ dựa trên 5 điểm chính và 4 trụ cột. Sự nhấn mạnh vào Trust trong E-E-A-T và sự khác biệt trong cách tiếp cận các bản cập nhật cốt lõi và thư rác là những bài học vô giá, giúp chúng ta hiểu rõ hơn về cách phản ứng khi trang web bị ảnh hưởng. Đừng quên thông báo quan trọng về API Google Trends (Alpha) mới, một công cụ mạnh mẽ hứa hẹn sẽ thay đổi cách chúng ta phân tích xu hướng tìm kiếm và lên kế hoạch nội dung.

Bài chia sẻ của mình cũng xoay quanh vấn đề về Indexing và cách xử lý sự cố SEO, giới thiệu về cộng đồng Google hỗ trợ người làm SEO. Sau đó mình nhận trả lời các câu hỏi trực tiếp từ người tham dự, cho họ tư vấn cũng như cách xử lý vấn đề bằng kinh nghiệm của mình.
Với những kiến thức này, tôi khuyến nghị các bạn, những chuyên gia SEO, hãy xem xét kỹ lưỡng cách Google hoạt động và áp dụng những hiểu biết này vào chiến lược của mình cho năm 2025. Hãy tập trung vào việc tạo nội dung ưu tiên con người, đáng tin cậy, và đảm bảo rằng các khía cạnh kỹ thuật của trang web của bạn hỗ trợ tối đa khả năng Google hiểu và lập chỉ mục nội dung đó. Đây không chỉ là về việc theo kịp các bản cập nhật, mà còn là về việc hiểu triết lý cốt lõi của Google để xây dựng một chiến lược SEO bền vững và hiệu quả.