
Haskell là gì?
Haskell là ngôn ngữ lập trình thuần hàm. Vì dùng nhiều khái niệm cấp cao, những code Haskell thường ngắn hơn các code khác và dễ bảo trì.
Bạn có quyền điều khiển các cấu trúc lặp để thực hiện một thao tác vài lần. Trong ngôn ngữ lập trình hàm thuần túy, bạn không ra lệnh cho máy tính làm như vậy, mà là nói cho máy biết cần phải làm điều gì.
Giai thừa của một số là tích các số nguyên từ 1 lên đến số đó; tổng của một danh sách các số thì bằng số thứ nhất cộng với tổng của tất cả các số còn lại, và cứ như vậy. Bạn thể hiện điều này dưới dạng các hàm. Bạn cũng không thể gán một biến bằng một giá trị nào đó để rồi sau này gán một giá trị khác.
Nếu bạn nói rằng a bằng 5, sau này bạn sẽ không thể nói nó bằng gì khác hơn vì bạn đã nói nó bằng 5 rồi. Nếu không, chẳng phải bạn đã nói dối ư? Vì vậy trong các ngôn ngữ lập trình hàm, một hàm không có hiệu ứng phụ nào. Điều duy nhất mà hàm thực hiện là tính một thứ gì dó rồi trả lại giá trị.
Thoạt đầu, điều này có vẻ hạn chế nhưng thực ra nó có một số hệ quả rất hay: nếu một hàm được gọi hai lần với các tham số giống hệt thì nó sẽ đảm bảo trả lại cùng kết quả.
Điều này được gọi là sự minh bạch trong tham chiếu và không chỉ cho phép các trình biên dịch hiểu được động thái của chương trình, mà còn giúp bạn dễ dàng suy luận (và thậm chỉ cả chứng minh) ràng một hàm được viết đúng, để từ đó xây dựng những hàm phức tạp hơn bằng cách gắn kết những hàm đơn giản lại với nhau.
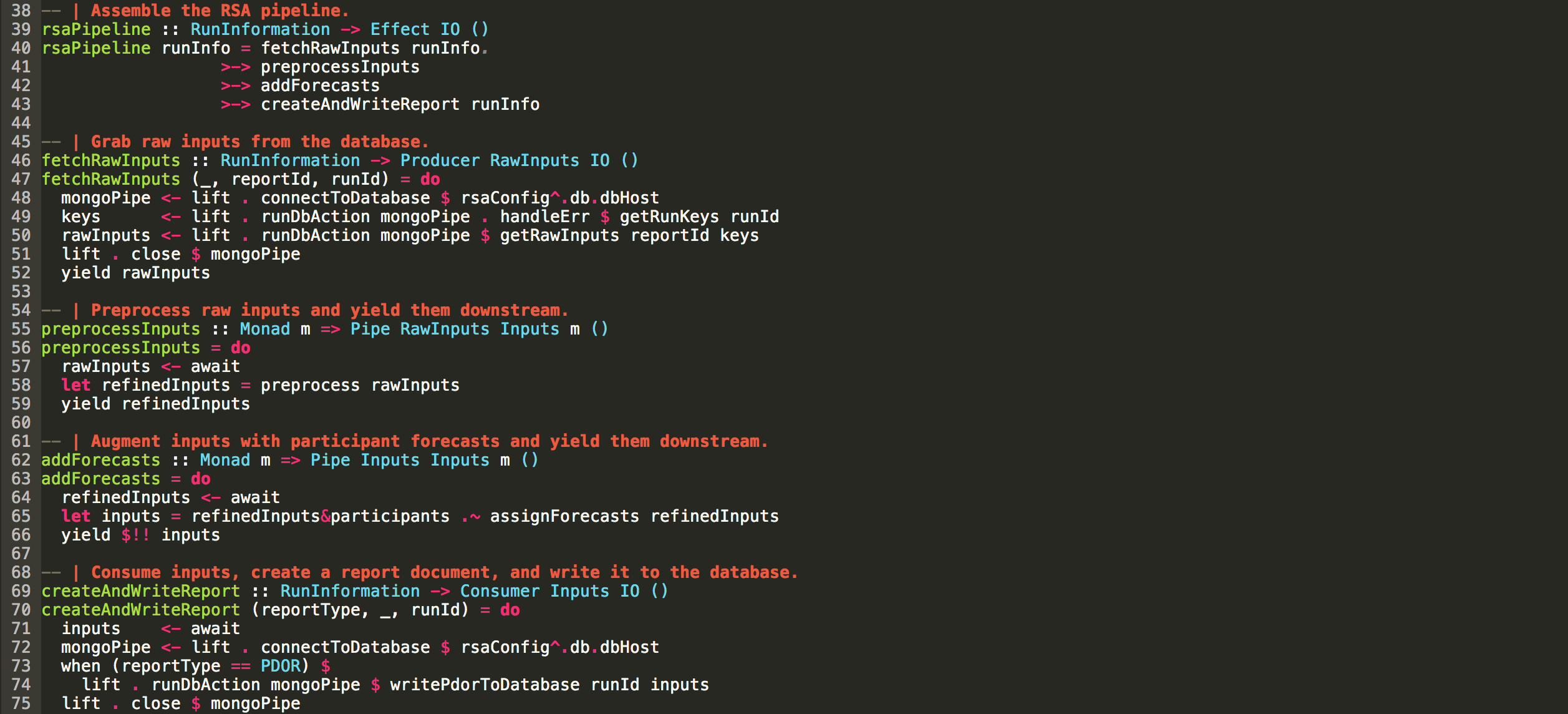
Giờ chúng ta đi sâu hơn vào Haskell nhé:
Functional Programming
• Imperative Programming: Lập trình mệnh lệnh, ta sử dụng câu lệnh để thay đổi trạng thái của chương trình. Ta sẽ hướng dẫn cho chương trình làm từng bước từ đầu đến cuối, hoặc lặp lại các câu lệnh nào đó, ...
• Declarative Programming: Lập trình khai báo, ta sẽ nói với chương trình ta muốn gì, chứ không phải là làm sao để thực hiện nó. Ta không ghi rõ các bước ra như trong lập trình mệnh lệnh.
Functional Programming (lập trình hàm) là một nhánh trong Declarative Programiming, mà trong đó, ta sẽ lấy hàm làm đơn vị cơ bản (tương tự trong lập trình hướng đối tượng thì đối tượng sẽ là đơn vị cơ bản).
Purity
Một hàm gọi là pure nếu nó nhận các tham số là giá trị và luôn trả về một giá trị nào đó mà không làm thay đổi bất kỳ trạng thái nào bên ngoài. Và với cùng một đầu vào, hàm sẽ trả về một giá trị tương ứng.
Ví dụ ta xét một hàm trong Swift như sau:
func add(_ a: Int, _ b: Int) -> Int {
return a + b
}
Hàm này là pure vì nó không làm thay đổi bất kỳ thứ gì bên ngoài. Tuy nhiên, hàm sau không pure vì cùng một đầu vào mà trả về giá trị khác nhau:
func radd(_ a: Int, _ b: Int) -> Int {
return Int.random(in: 0...10) * (a + b)
}
Nhưng như thế thì việc in một dòng chữ ra màn hình cũng gây ra sự thay đổi trạng thái rồi, vậy thì làm cách nào mà chỉ sử dụng các hàm thuần khiết? Trong Functional Programming, ta cũng phải có các thao tác IO, là các thao tác impure, chúng sẽ bị gói gọn vào một nơi để thuận tiện cho việc quản lý. Mục tiêu của Functional Programming là làm giảm tối đa hiệu ứng phụ bằng cách cô cập chúng, chứ không phải bỏ hoàn toàn.
Immutability
Sẽ không có sự thay đổi giá trị một biến (variable) số trong Functional Programming, một giá trị được lưu vào một variable thì sẽ mãi mãi nhận giá trị đó, nhìn chung thì nó là const variable. Các bạn đã học Swift chắc chắn sẽ quen sử dụng nhiều đến từ khóa let, chắc có nhiều lý do cho việc này, ta thấy rằng nó giảm thiểu được nhiều lỗi khi dùng const variable(và một trong những lý do chính là swiftc sẽ gầm rú lên mỗi khi một biến chỉ gán một lần mà ta lại sử dụng var)
Recursive
Trong Functional Programming, ta không có các từ khóa như for, while, repeat, forEach, .... Để thực hiện các vòng lặp, ta sẽ sử dụng đệ quy. Ví dụ:
int max(int const* const arr, const int n) {
if (n == 1) return *arr;
int const carry = max(arr + 1, n - 1);
if (carry > *arr) return carry;
return *arr;
}
Một hàm tìm giá trị lớn nhất trong một mảng số nguyên bằng đệ quy hẳn đã quen thuộc với nhiều người. Ở đây int const* const chỉ ra rằng arr phải trỏ đến một địa chỉ cố định và các giá trị nó trỏ đến phải cố định để bảo toàn tính immutability (trình dịch sẽ gần rú mỗi khi bạn dám cả gan thay đổi gì đó).
Haskell
Haskell là ngôn ngữ lập trình hàm thuần túy (Pure Functional Programming), là một ngôn ngữ biên dịch, và là một ngôn ngữ kiểu tĩnh, nhưng đừng quá lo lắng, trình biên dịch sẽ giúp đỡ ta rất nhiều trong việc tự suy kiểu. Haskell có tính lười biếng (Lazy evaluation), trừ khi buộc phải làm thì Haskell sẽ không bao giờ thực thi tính toán. Một ví dụ đơn giản ta có hai hàm repeat và take như sau:
repeat :: a -> [a]
repeat x = x : repeat x
take :: Int -> [a] -> [a]
take n _ | n <= 0 = []
take _ [] = []
take n (x:xs) = x : take (n-1) xs
Nếu là Python, ta sẽ viết như sau:
def repeat(x):
return [x] + repeat(x)
def take(n, seq):
if n <= 0 or seq == []: return []
return [x] + take (n-1) seq[1:]
Tuy nhiên, trong Python, khi ta gọi take(3, repeat(7)), chương trình sẽ tính repeat(7) trước và mới take sau. Tuy nhiên, khi tính repeat(7) trước thì ta sẽ bị vả ngay maximum recursion depth exceeded vì repeat(7) là một list gồm vô hạn các số 7 (Ta có thể sửa hàm repeat để cho nó trở thành một generator nhưng đây không phải là mục đích chính của bài viết). Giờ hãy nhìn qua Haskell, nếu ai chưa biết thì f x1 x2 ... là các triển khai một hàm f với các tham số x1, x2, ... và x:xs có thể được hiểu là x là phần tử đầu tiên của một list và xs được hiểu như "khả năng cao là phần còn lại" (không phải là "phần còn lại", chỉ là "khả năng cao là phần còn lại"). Giờ hãy xem các Haskell triển khai hàm take 3 (repeat 7):
take 3 (repeat 7)
= take 3 (7 : repeat 7)
= 7 : take 2 (repeat 7)
= 7 : take 2 (7 : repeat 7)
= 7 : 7 : take 1 (repeat 7)
= 7 : 7 : 7 : take 0 (repeat 7)
= 7 : 7 : 7 : []
= [7, 7, 7]
Với xét mẫu (x:xs) ở định nghĩa, nó sẽ chuyển repeat 7 thành 7 : repeat 7 mỗi khi được gọi. Mọi thứ thuần Haskell đều lười, nhưng vẫn có một hàm cho phép ta tính toán trước giá trị tham số trước khi được thực thi (và tất nhiên nó không thể nào viết hoàn toàn bằng Haskell). Tính lười biếng của Haskell cũng gây ra một số phiền phức:
lazySum (Num a) => [a] -> a
lazySum = go 0
where
go curr [] = curr
go curr (x:xs) = go (curr + x) xs
Hàm này nhận vào một danh sách và trả về tổng các phần tử của danh sách đó, với tính lười biếng của ngôn ngữ, nó sẽ thực hiện như sau:
lazySum [1, 2, 3, 4]
go 0 [1, 2, 3, 4]
go (1 + 0) [2, 3, 4]
go (2 + (1 + 0)) [3, 4]
go (3 + (2 + (1 + 0))) [4]
go (4 + (3 + (2 + (1 + 0)))) []
4 + (3 + (2 + (1 + 0)))
4 + (3 + (2 + 1))
4 + (3 + 3)
4 + 6
10
Có quá nhiều biểu thức chưa được evaluate, Haskell lúc này tạo ra quá nhiều thunk. Để hạn chế điều này, như đã giới thiệu ở trên, có một hàm cho phép evaluate một giá trị nào đó trước, Haskell cho ta seq:
seq a b = b
a `seq` b = b
Trong đó a sẽ được evaluate, hoặc đơn giản hơn ta chỉ cần đặt ! trước biến ta cần evaluate trước khi hàm chạy với cờ lệnh -XBangPatterns. Như vậy ta sẽ viết lại hàm trên như sau:
betterSum (Num a) => [a] -> a
betterSum = go 0
where
go curr [] = curr
go curr (x:xs) = curr `seq` go (x + curr) xs
hoặc:
betterSum (Num a) => [a] -> a
betterSum = go 0
where
go curr [] = curr
go !curr (x:xs) = go (x + curr) xs
Và ta hãy nhìn cách mà hàm này hoạt động tốt hơn trước rất nhiều:
betterSum [1, 2, 3, 4]
go 0 [1, 2, 3, 4]
go (1 + 0) [2, 3, 4]
go (2 + 1) [3, 4]
go (3 + 3) [4]
go (4 + 6) []
4 + 6
10
Với phép &&, thì nó cũng là một hàm:
(&&) :: Bool -> Bool -> Bool
True && x = x
False && _ = False
Ta thực hiện hai phép toán sau:
False && (10^1000000 > 5)
False &&! (10^1000000 > 5)
Haskell có kiểu tĩnh.
Khi bạn biên dịch chương trình vừa viết, thì trình biên dịch sẽ hiểu được đoạn mã nào là một số, đoạn mã nào là một chuỗi kí tự, vân vân. Điều này đồng nghĩa với việc rất nhiều lỗi tiềm ẩn được phát hiện lúc biên dịch. Nếu bạn cố gắng cộng một số và một chuỗi kí tự lại với nhau, trình biên dịch sẽ gào lên. Haskell sử dụng một hệ thống kiểu rất tốt và có khả năng suy luận kiểu. Nghĩa là bạn không cần phải gắn cụ thể từng đoạn mã lệnh với một kiểu riêng, vì hệ thống kiểu có thể hình dung ra điều này một cách rất thông minh. Nếu bạn nói a = 5 + 4, bạn sẽ không cần phải bảo Haskell biết rằng a là một con số; nó có thể tự hình dung ra được. Suy luận kiểu cũng giúp cho mã lệnh bạn viết được tổng quát hơn. Nếu như một hàm bạn viết ra nhận hai tham số và cộng chúng lại với nhau mà không nói rõ kiểu của các tham số này thì hàm sẽ tính được với hai tham số bất kì nào có biểu hiện giống kiểu số.
Phép tính sau sẽ chậm hơn vì ta buộc Haskell phải tính giá trị phía sau trong khi lại không cần thiết.
Việc Haskell biên dịch ra những gì và thời gian chạy ra sao là điều khó có thể đoán trước được, cùng nhớ bộ thu dọn rác nên Haskell thường không phù hợp với các hệ thống nhúng, nơi mà cần quản lý bộ nhớ và đảm bảo độ trễ một cách tuyệt đối. Ngoài ra mã nguồn của một file nhị phân dịch từ Haskell là rất lớn nên không phù hợp với các hệ thống nhúng với lượng bộ nhớ hạn chế. Cũng như viết một ứng dụng bằng các Framework C++ như Qt thì Haskell trong lập trình ứng dụng cũng rất là đau đớn. Haskell được sử dụng tốt nhất khi muốn tạo một compiler, concurenccy hay phân tích cú pháp...
Cú pháp của ngôn ngữ mang tính toán học hơn là tin học, ví dụ, để biểu thị một tập hợp các số chẵn trong trong đoạn từ 1 đến 10, một cách toán học, ta sẽ viết \left\{x \in \overline{1, 10} |\; 2 | x\right\} hoặc \left\{x | x \in \overline{1, 10} \; \wedge\; 2 | x\right\}. Với cách viết thứ 2, ta sẽ hiện thực nó bằng Haskell với phép chuyển đơn giản \in thành <-:
[x | x <- [1..10], x `mod` 2 == 0]
Kết quả sẽ trả về [2, 4, 6, 8, 10]. Để liệt kê kê ra các bộ 3 số nguyên không âm có tổng bằng 6 thì ta sẽ có:
[(a, b, c) | a <- [0..6], b <- [0..6], c <- [0..6], a + b + c == 6]
Tôi học Haskell cũng chỉ vì điều này, các mô hình công thức truy hồi, tổ hợp, ... đều có thể được Haskell hiện thực. Ví dụ, với bài toán đếm xem có bao nhiêu bộ n số nguyên không âm có tổng là m. Tất nhiên theo chia kẹo Euler thì kết quả sẽ là \binom{n - 1}{m + n - 1}, tuy nhiên hãy giả vờ ngây thơ như những gì người ta đã làm với định lý Bayes trong Machine Learning, ta sẽ liệt kê hết vào một danh sách và đếm số phần tử của danh sách đó:
tupleWithSum :: Integer -> Integer -> [[Integer]]
tupleWithSum 1 m = [[m]]
tupleWithSum n m = [x:xs | x <- [0..m], xs <- tupleWithSum (n - 1) (m - x)]
Ta thực hiện length $ tupleWithSum 3 6, kết quả ra 28 chính bằng \binom{3 - 1}{8 + 3 - 1}. Hãy nhìn vào hàm số đó và thiết kế nó với mô hình toán học, nó sẽ được viết S_{n + 1, m} = \left\{(x, A) \;|\; x \in \overline{0,m},\; A \in S_{n-1, m - x} \right\}.
Nhờ Haskell, tôi mới biết cách triển khai một cái gì đó từa tựa quy hoạch động thông qua đệ quy:
fib = go 0 1
where
go a _ 0 = a
go a b n = go b (a + b) (n - 1)
Nhìn chung, Haskell gây cho tôi nhiều hứng thú hơn tôi tưởng, cho dù nó khó, nhưng nó rất đáng để học cho việc luyện tư duy lập trình.